
From “Tables (pandas)”
Contents
From “Tables (pandas)”#
Last updated: 2023-02-25 13:37:49
Exercise 05-d#
2021
Exercise 05-g#
import pandas as pd
students = pd.read_csv("data/students.csv")
# Total number of students in 'Ben-Gurion Univ. of the Negev'
students["Ben-Gurion Univ. of the Negev"].sum()
543615
# Total number of students in 'Ariel University
students["Ariel University"].sum()
46633.0
students["year"] = pd.to_numeric(students["year"].str.split("/").str[0]) + 1
# Range of observed years
x = students["year"]
[x.min(), x.max()]
[1970, 2020]
# Year with highest number of students in 'Ben-Gurion Univ. of the Negev'
students["year"][students["Ben-Gurion Univ. of the Negev"].idxmax()]
2011
# Year with highest number of students in 'Weizmann Institute of Science'
students["year"][students["Weizmann Institute of Science"].idxmax()]
2020
Exercise 05-h#
import numpy as np
import pandas as pd
kinneret = pd.read_csv("data/kinneret_level.csv")
kinneret = kinneret.rename(columns = {"Survey_Date": "date", "Kinneret_Level": "value"})
kinneret["date"] = pd.to_datetime(kinneret["date"])
dates = pd.date_range(kinneret["date"].min(), kinneret["date"].max())
kinneret = kinneret.set_index("date")
kinneret = kinneret.reindex(dates, fill_value = np.nan)
/tmp/ipykernel_12631/3672199559.py:5: UserWarning: Parsing dates in DD/MM/YYYY format when dayfirst=False (the default) was specified. This may lead to inconsistently parsed dates! Specify a format to ensure consistent parsing.
kinneret["date"] = pd.to_datetime(kinneret["date"])
kinneret["value"].plot();
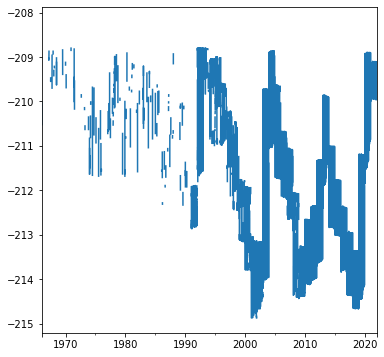
# Proportion of days without water level measurement
kinneret["value"].isna().mean()
0.5348905538416336
# Days with lowest observed water level
kinneret[kinneret["value"] == kinneret["value"].min()]
| value | |
|---|---|
| 2001-11-25 | -214.87 |
| 2001-11-26 | -214.87 |
| 2001-11-27 | -214.87 |
| 2001-11-28 | -214.87 |
| 2001-11-29 | -214.87 |
# Length of longest consecutive period without a measurement
counter = 0
maxcount = 0
for i in range(0, kinneret.shape[0]):
current = kinneret["value"].iloc[i]
if np.isnan(current):
counter = counter + 1
else:
if(counter > maxcount):
maxcount = counter
counter = 0
maxcount
245