
Conditionals and loops#
Last updated: 2025-01-15 17:42:41
Introduction#
In the previous chapter (see Python basics), we learned to create, access, and modify Python’s basic data structures. In this chapter, we are going to learn several important techniques of writing code, thus expanding our set of tools for writing Python code beyond simple data creation and access.
First, we are going to learn about control flow, a term that encompasses two techniques:
Conditionals—methods for conditional code execution, such as
if-elseconditionals (see Conditionals)Loops—methods for repeated code execution, such as
forloops (see for loops)
Then, we introduce the basic methods for reading plain text files (Working with files), and a more specific method to read the tabular CSV format (Reading CSV files). As we will see, these methods involve both flow control techniques:
Loops—to go over the lines in a file, one by one, and
Conditionals—to do something with only those lines that satisfy a given condition.
Finally, we learn about:
The range function—which is used create numeric sequences
List comprehension—a powerful technique to write a certain type of loops more concisely
Defining functions—to repeat the same calculation in more then one place in our code
Conditionals#
The if conditional#
Conditionals are used to condition the execution of a particular code section based on a criterion. The most common and useful conditional is if. For example, the following expression prints 'It is hot!' only if latitude is smaller than 66.5. We are using the print function to explicitly indicate that the value needs to be printed:
if latitude < 66.5:
print('It is hot!')
Note the syntax of the if conditional:
if condition:
expression1
expression2
...
The if keyword is followed a condition, which should be a boolean value, or an expression that can be evaluated as a boolean value, ending with a colon (:). Next comes a block of code, comprised of one or more expressions and marked by indentation. If condition is True, the block of code is executed. If condition is False, the block of code is ignored.
For example, if latitude is equal to 31.25, then latitude<66.5 returns True. Therefore, the print expression would be executed, printing the string 'It is hot!' in the console:
latitude = 31.25 # Latitude of Beer-Sheva, Israel
if latitude < 66.5:
print('It is hot!')
It is hot!
If latitude is 77.5, then the expression latitude<66.5 returns False. Therefore, the print expression is ignored, and nothing happens:
latitude = 71.5 # Latitude of Nuugaatsiaq, Greenland
if latitude < 66.5:
print('It is hot!')
The if-else conditional#
The if conditional may optionally be expanded, adding the else keyword followed by a second code block:
if condition:
expression1
expression2
...
else:
expression1
expression2
...
In this if-else variant, one of the two code blocks is always executed. If condition is True then the first code block is executed. If condition is False, then the second code block is executed. Here are examples of these two scenarios, respectively:
latitude = 31.25 # Latitude of Beer-Sheva, Israel
if latitude < 66.5:
print('It is hot!')
else:
print('It is cold!')
It is hot!
latitude = 71.5 # Latitude of Nuugaatsiaq, Greenland
if latitude < 66.5:
print('It is hot!')
else:
print('It is cold!')
It is cold!
Indentation in Python#
As mentioned above, the expressions that follow if and else are indented. This is not a coincidence. In fact, Python recognizes multi-line code blocks through indentation. For example, in the context of a conditional, indentation is our way to tell the Python interpreter “these expressions belong to the if statement”. You can use any number of spaces or tabs for indentation, as long as you are consistent. The convention, however, is to use four spaces for each level of indentation. For example, consider the following example which has several expressions inside two levels of indentation:
x = -2
if x >= 0:
if x == 0:
print('Zero')
else:
print('Positive number')
else:
print('Negative number')
Negative number
In many other programming languages (such as R and JavaScript) indentation is ignored by the computer, and code sections are marked by other means (such as { and }). In Python, indentation is the only way to mark code sections. Therefore, when writing Python code you must pay close attention to indentation. Make sure there is no unnecessary indentation, and that indentation is uniform (preferably using four spaces).
As we will see later on, marking code sections using indentation is not specific to conditionals. It is also used in all other contexts where we need to mark a code block, such as in for loops (see for loops), in file contexts (see Using contexts (with)), and in function definitions (see Defining functions).
for loops#
What are for loops?#
Loops are used to run a particular code section more than once. For example, we may want to apply the same calculation for every element in a list (see Lists (list)), for each of 100 separate files, and so on. Python has two types of loops, namely:
whileloops—A (potentially) infinite loop with a stopping conditionforloops—An iteration over a sequence
In this book we focus on for loops, which is by far the most useful type of loop when working with data.
for loops are used to iterate over sequences. This means that the for loop executes a particular code section for each item in the sequence. Often, the code section does something with each particular “item” in the sequence. The “sequence” we iterate over is often a list, but it can also be a tuple, a dictionary, a set, or a string (or any other iterable object).
As we will see later on, for loops can even be used to iterate over sequences generated in “real-time”, such as lines read one-by-one from a file (Working with files), which means we can process very large data structures without loading all data into memory at once.
The for loop syntax#
The syntax of a for loop is as follows:
for i in sequence:
expression1
expression2
...
Note the following components:
The
forkeywordName of the variable that gets consecutive values (
i)The
inkeywordThe object where consecutive values come from (
sequence). This is typically a “collection” data type such as alistortuple(see Data types—overview), or another type of iterable object (i.e., that can be iterated) such as arangeobject (see The range function), or a file connection (see Reading CSV files).Colon (
:)Code block that gets executed in each iteration, typically using the current value (
i)
Here is an example of a for loop:
fruits = ['Orange', 'Banana', 'Mango', 'Apple']
for i in fruits:
print(i)
Orange
Banana
Mango
Apple
In this example, we go over the elements of a list named fruits. For each element i, we execute the expression print(i). As a result, we get a consecutive printout of all elements in fruits.
Exercise 03-a
Define a list named
lunch, as shown below.Use a
forloop and conditionals to create a dictionary with the count of each item inlunch.Hint: create an empty dictionary, then use a
forloop to go over the items, and a conditional to add a new item with count1(if it is not yet in the dictionary), or to increment an existing item count.Answer:
{'Salad':2,'Egg':1,'Beef':1,'Potato':3,'Tea':1,'Coffee':1}
lunch = [
'Salad',
'Salad',
'Egg',
'Beef',
'Potato',
'Tea',
'Potato',
'Potato',
'Coffee'
]
Using enumerate#
Sometimes we need to work with both the index and value of the sequence we iterate on. To do that, we can encompass the sequence inside enumerate. That way, each value becomes a tuple of the form (index,value). For example, we are going to use enumerate when stacking raster bands from separate files (see Stacking raster bands), where the for loop requires both:
the value (file path to read from), and
the index (index of the raster band to write into).
Here is an example of using enumerate in a for loop. The difference, compared to the last example, is that the sequence we iterate on is now enumerate(fruits), instead of just fruits:
for i in enumerate(fruits):
print(i)
(0, 'Orange')
(1, 'Banana')
(2, 'Mango')
(3, 'Apple')
Here is the last value of i:
i
(3, 'Apple')
We can see that it is indeed a tuple, using type:
type(i)
tuple
If necessary, we can modify the starting point of the indices (default is 0), using the start parameter of enumerate. For example:
for i in enumerate(fruits, start=1):
print(i)
(1, 'Orange')
(2, 'Banana')
(3, 'Mango')
(4, 'Apple')
Finally, we can also split the indices and values into separate variables, so that we do not need to deal with tuples. For example, in the following version we have the variables index and value to access the index and value in each for loop iteration:
for index, value in enumerate(fruits, start=1):
print(index)
print(value)
1
Orange
2
Banana
3
Mango
4
Apple
Working with files#
Overview#
Python provides built-in methods for reading (and writing) plain text files, such as CSV, using line-by-line iteration. Although we will later learn about a concise approach to read CSV files, all at once, using the pandas package (see Reading from file), the basic approach which we learn in this section has some advantages, and therefore worthwhile to be familiar with. Specifically:
Using external packages, such as
pandas, may be impossible in some situations, such as systems that are not connected to the internet or have other security restrictions that prevent downloading and installation of third-party packages. In some situations we may wish to limit reliance on third-party packages for other reasons, such as making our code as reproducible and stable as possible.Reading a file by iterating along rows has a very small memory footprint, since only the current row is stored in memory at any given time. This makes it possible to process huge files that cannot fit into memory all at once.
Before we move on to a more specific example of reading a CSV file (see Reading CSV files), let us go over a minimal example which works with any type of plain text file (not just CSV) and demonstrates the general principles of reading a file in Python, namely the concepts of a file connection object, and reading one line at a time.
File object and reading lines#
To read from a text file in Python, we first need to create a file connection object, using the open function. The open function has three important arguments:
The file path, such as
'data/gtfs/stops.txt'(see File paths)The mode, typically
'r'for text reading mode (the default), or'w'for text writing modeThe encoding, such as
'utf-8'or'utf-8-sig'
The concept of file encoding deserves a few notes. In general, encoding defines how the information in the file is interpreted by the computer. In order for the information to be interpreted correctly, the encoding setting must match to the encoding which was used when creating the file in the first place. If the encoding is left unspecified, the system default will be used. In case the system default does not match the file encoding, the contents may be interpreted incorrectly, or there may be an error and contents will not be read at all. Anyone working with data, especially in languages other than English, will encounter this situation sooner or later. The problem is that text files, including CSV, do not always store the encoding specification internally, as part of the file. Then, the user must figure out the right encoding from context (such as metadata, if any), or through trial and error.
UTF-8 is the most widely used file encoding when working with data. All CSV sample data files we use in this book are encoded in UTF-8. The difference between 'utf-8' or 'utf-8-sig' is that the latter specifies the input file has a Byte Order Mark (BOM) signature, namely \ufeff. The BOM is omitted from the result when the right encoding is specified in open. For example, try opening the file connection with open('data/gtfs/stops.txt',encoding='utf-8'), then inspecting the contents of the first line (see below). You should see \ufeff at the beginning of the string.
Note
For more information on the difference between 'utf-8' or 'utf-8-sig', check out the following threads:
For example, the following expression creates a connection to the file 'stops.txt' from the sample data (see Sample data), in 'r' (reading) mode, using the 'utf-8-sig' encoding, which is the right encoding for this file. The file connection object is assigned to a variable named f:
f = open('data/gtfs/stops.txt', 'r', encoding='utf-8-sig')
f
<_io.TextIOWrapper name='data/gtfs/stops.txt' mode='r' encoding='utf-8-sig'>
To demonstrate reading from a file, we will use the .readline method of the connection object. The .readline method reads one line at a time. For example, the following expression reads the first line in 'stops.txt', and assigns the resulting string to x:
x = f.readline()
x
'stop_id,stop_code,stop_name,stop_desc,stop_lat,stop_lon,location_type,parent_station,zone_id\n'
Keep in mind that strings obtained from a text file may include special characters, such as newline ('\n'). These are interpreted when printing the string with print:
print(x)
stop_id,stop_code,stop_name,stop_desc,stop_lat,stop_lon,location_type,parent_station,zone_id
If we run .readline once again, we get the string with the contents of the second line in the file, and so on, until the final line is reached. Here, we are reading the next three lines (i.e., lines 2-4):
f.readline()
"1,38831,בי''ס בר לב/בן יהודה,רחוב: בן יהודה 74 עיר: כפר סבא רציף: קומה: ,32.183985,34.917554,0,,38831\n"
f.readline()
'2,38832,הרצל/צומת בילו,רחוב: הרצל עיר: קרית עקרון רציף: קומה: ,31.870034,34.819541,0,,38832\n'
f.readline()
'3,38833,הנחשול/הדייגים,רחוב: הנחשול 30 עיר: ראשון לציון רציף: קומה: ,31.984553,34.782828,0,,38833\n'
The 'stops.txt' file is one of ten CSV files comprising the GTFS dataset (see the gtfs directory in the Sample data). The GTFS dataset describes public transport routes and timetables in Israel, in the standard format known as General Transit Feed Specification (GTFS). We are going to elaborate on the structure of the dataset later on (see What is GTFS?). In this chapter, we will only be working with the 'stops.txt' file, which describes the public transport stops. For example, it contains the following columns we will be interested in:
'stop_name'—Stop name'stop_lon'—Stop longitude, in decimal degrees'stop_lat'—Stop latitude, in decimal degrees
Keep in mind that:
columns in a CSV file are separated by commas, and
the first line is (usually) the header, i.e., column names (see Reading CSV files).
It is easier to understand the columns structure when viewing the file in a spreadsheet software (Fig. 22).
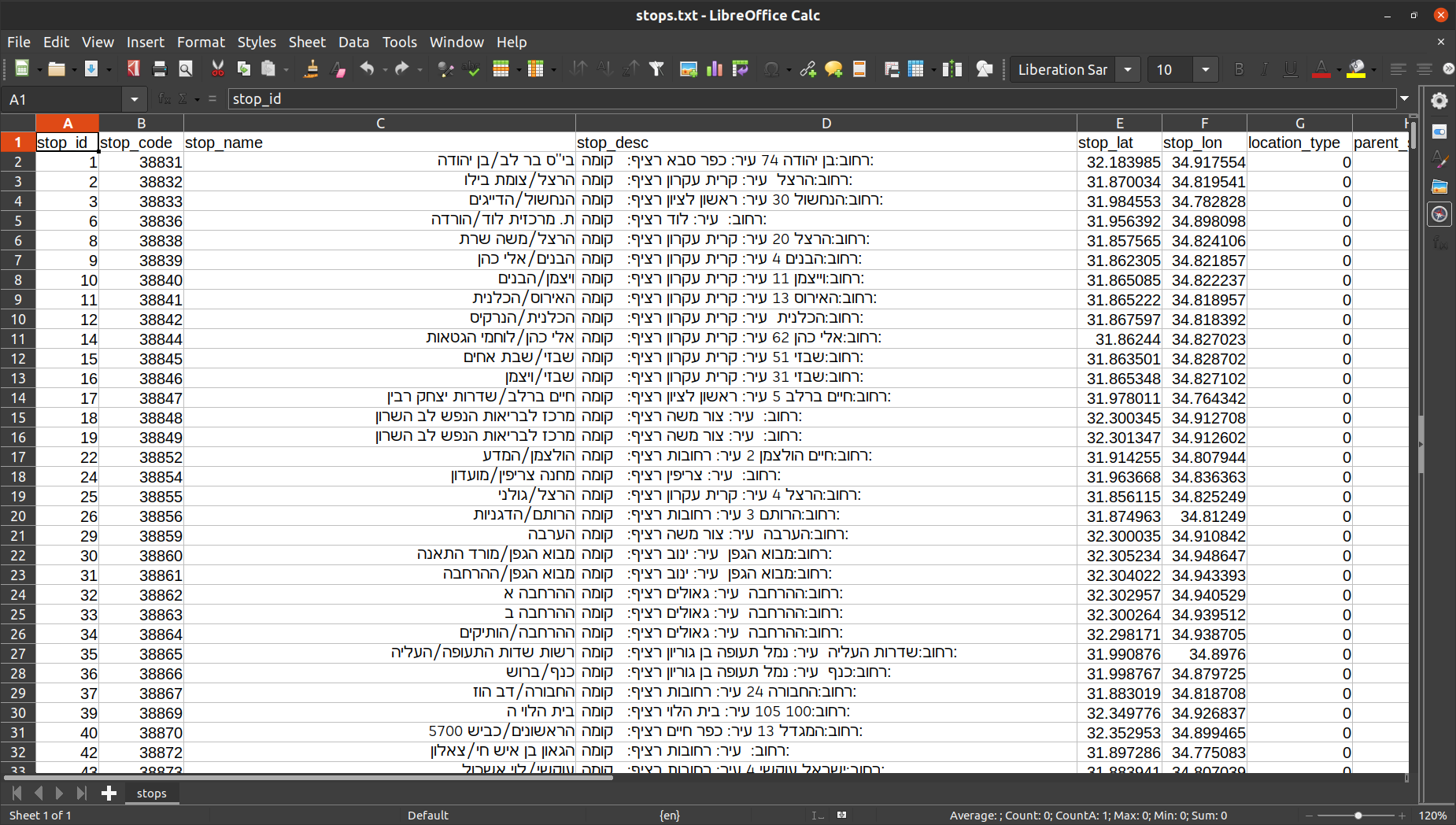
Fig. 22 The 'stops.txt' file from the GTFS dataset when opened in a spreadsheet software (LibreOffice Calc)#
When we are done working with the file, the file connection needs to be closed using .close:
f.close()
Closing a file connection is necessary to make sure that:
All information is actually written into the file (when in writing mode)
The memory is freed
We will learn about automated closing of file connections, using with, later on (see Using contexts (with)).
Reading CSV files#
Comma Separated Values (CSV) is a commonly used plain text format to store tabular data. In a CSV file, each line represents a table row, whereas columns are separtated by commas (thus the “Comma Separated” part). The first line usually contains the column names, also separated by commas.
CSV files are a special case of plain text files, which means they can be read using general methods such as .readline as shown above (see File object and reading lines). However, there are also more specialized methods to read CSV files, such as the csv.DictReader function, combined with next, defined in the standard csv Python package. The advantage of csv.DictReader, compared to the general readlines method (see File object and reading lines), is that the CSV lines are automatically split by commas and placed into a dict where:
keys are the column names (by default, obtained from the first line)
values are the current row values
For example, the following code section reads and prints the first 4 rows (excluding the header) in 'stops.txt':
import csv
f = open('data/gtfs/stops.txt', 'r', encoding='utf-8-sig')
reader = csv.DictReader(f)
row = next(reader)
print(row)
row = next(reader)
print(row)
row = next(reader)
print(row)
row = next(reader)
print(row)
f.close()
{'stop_id': '1', 'stop_code': '38831', 'stop_name': "בי''ס בר לב/בן יהודה", 'stop_desc': 'רחוב: בן יהודה 74 עיר: כפר סבא רציף: קומה: ', 'stop_lat': '32.183985', 'stop_lon': '34.917554', 'location_type': '0', 'parent_station': '', 'zone_id': '38831'}
{'stop_id': '2', 'stop_code': '38832', 'stop_name': 'הרצל/צומת בילו', 'stop_desc': 'רחוב: הרצל עיר: קרית עקרון רציף: קומה: ', 'stop_lat': '31.870034', 'stop_lon': '34.819541', 'location_type': '0', 'parent_station': '', 'zone_id': '38832'}
{'stop_id': '3', 'stop_code': '38833', 'stop_name': 'הנחשול/הדייגים', 'stop_desc': 'רחוב: הנחשול 30 עיר: ראשון לציון רציף: קומה: ', 'stop_lat': '31.984553', 'stop_lon': '34.782828', 'location_type': '0', 'parent_station': '', 'zone_id': '38833'}
{'stop_id': '4', 'stop_code': '38834', 'stop_name': 'משה פריד/יצחק משקה', 'stop_desc': 'רחוב: משה פריד 5 עיר: רחובות רציף: קומה: ', 'stop_lat': '31.888325', 'stop_lon': '34.790700', 'location_type': '0', 'parent_station': '', 'zone_id': '38834'}
Here is what is happening in the above code section:
First, we import the
csvpackage (see Loading packages)Next, we create a file connection object to the CSV file (see File object and reading lines)
Then, we create a “reader” object, applying the
csv.DictReaderfunction on the file connectionThen, we apply the
nextfunction on thecsv.DictReaderobject, which reads one line at a time into adict, consecutively going through rows 2-4 in the fileFinally, the file connection is closed using
.close
Note how, by default, the first row is assumed to be the header and therefore only used to obtain the keys. That is, the first use of next actually returns the 2nd row in the CSV file.
Note
There is also a csv.reader method, which returns a list of row values (rather than a dict as in the case of csv.DictReader), including the first row (!). For example, try executing reader=csv.reader(file), and then, consecutively, next(reader). Accessing the CSV file values through list indices may be easier for files that have two or three columns. However, accessing the values through dict keys (i.e., the column names) is more convenient with files that have many columns (such as 'stops.txt').
Exercise 03-b
Create a new code cell with the expressions to open the file connection and to create the file reader.
Then create another cell with the expression
next(reader).Execute the second code cell repeatedly several times. You should see the contents of consecutive lines being read from the CSV file.
When reading a CSV file using csv.DictReader and next, each row in the CSV file is being read as a dict of strings (even if some of the values are numeric). For example, here is the contents of the 4th row in 'stops.txt':
row
{'stop_id': '4',
'stop_code': '38834',
'stop_name': 'משה פריד/יצחק משקה',
'stop_desc': 'רחוב: משה פריד 5 עיר: רחובות רציף: קומה: ',
'stop_lat': '31.888325',
'stop_lon': '34.790700',
'location_type': '0',
'parent_station': '',
'zone_id': '38834'}
To get a particular value from a given row, we can use the ordinary method of accessing dict values (see Accessing dict values). For example, the following expression returns the value in the 'stop_name' column:
row['stop_name']
'משה פריד/יצחק משקה'
whereas the following expression returns the value in the 'stop_lat' (stop latitude) column:
row['stop_lat']
'31.888325'
Here is a slightly modified code block, which prints just the values in the 'stop_name' column, rather than the entire rows:
import csv
f = open('data/gtfs/stops.txt', 'r', encoding='utf-8-sig')
reader = csv.DictReader(f)
row = next(reader)
print(row['stop_name'])
row = next(reader)
print(row['stop_name'])
row = next(reader)
print(row['stop_name'])
row = next(reader)
print(row['stop_name'])
f.close()
בי''ס בר לב/בן יהודה
הרצל/צומת בילו
הנחשול/הדייגים
משה פריד/יצחק משקה
In practice, we usually need to go over the entire file, not just the first few rows, which makes using next impractical. Instead, we can use a for loop such as the following one:
import csv
f = open('data/gtfs/stops.txt', 'r', encoding='utf-8-sig')
reader = csv.DictReader(f)
for row in reader:
x = row
# Do something with each row
f.close()
Exercise 03-b
What do you think is the value of
xafter running the above code block? Printxto check your answer.
In each iteration of the for loop, the row object contains the dict with values from that particular row, which we can do something with.
Keep in mind that you can only go through a file connection, using methods such as .readline, next, or a for loop, or any combination of them, only once. When the file contents are “exhausted”, such as when trying to run a for loop on the same csv.DictReader for a second time, there will be no output. Similarly, if you run next to get the contents of the 1st row in the file, and subsequently run a for loop on the same file connection, then the for loop will start from the 2nd row—because the 1st was already read. Therefore, if you need to go over the file again, you need to re-create the file connection.
Exercise 03-c
Calculate the number of rows (i.e., lines) in
'stops.txt', excluding the first rowHint: Set a counter variable to zero, then increment it by
1in each iteration of aforloop that goes over the rows
Writing CSV files#
Writing to CSV files is conceptually similar to reading. We will not go into details, but here is a small self-contained example that you can try to get the idea:
import csv
f = open('output/packages.csv', 'w')
writer = csv.writer(f)
writer.writerow(['Package', 'Functionality', 'Website'])
writer.writerow(['numpy', 'Arrays', 'https://numpy.org/'])
writer.writerow(['pandas', 'Tables', 'https://pandas.pydata.org/'])
writer.writerow(['shapely', 'Vector geometries', 'https://shapely.readthedocs.io/'])
writer.writerow(['geopandas', 'Vector layers', 'https://geopandas.org/'])
writer.writerow(['rasterio', 'Rasters', 'https://rasterio.readthedocs.io/'])
f.close()
The above code section writes the information shown in Table 1 into a CSV file named 'packages.csv' in the 'output' directory. Beware that opening a file in writing 'w' mode deletes the contents when the file already exists!
Note
The above code uses csv.writer, which is analogous to csv.reader, as both work with lists. Perhaps you can guess that there is also a csv.DictWriter function, which is analogous to csv.DictReader (see Reading CSV files)—both working with dictionaries.
Using contexts (with)#
When opening a file to do something with it, such as reading from it, we need to open it at the beginning and then .close it at the end (see File object and reading lines). This is essential to make sure that memory is freed and all information pending to be written is actually written.
To make sure we do not forget to “close” a file connection, we can use the with keyword to create a file connection context. The with expression is followed by a code block where we do something with the file connection. After the code block is completed, the file connection is automatically closed.
For example, instead of the for loop from the last example (see Reading CSV files):
f = open('data/gtfs/stops.txt', 'r', encoding='utf-8-sig')
reader = csv.DictReader(f)
for row in reader:
x = row
# Do something with each row
f.close()
we can do this:
with open('data/gtfs/stops.txt', 'r', encoding='utf-8-sig') as f:
reader = csv.DictReader(f)
next(reader)
for row in reader:
x = row
# Do something with each row
Namely, instead of f=open(...) and f.close(), we have a code block that begins with with open(...) as f:, followed by the same code as before, only without the .close part.
Exercise 03-d
Calculate the range of longitudes and latitudes of all stops in
'stops.txt', i.e., the bounding box of the point layer that the file represents: \(lon_{min}\), \(lat_{min}\), \(lon_{max}\), and \(lat_{max}\)Print the result as an array of the form
[xmin,ymin,xmax,ymax]Go through the following steps:
Define a variable named
xminto hold the value of \(lon_{min}\). Initialize it with the value ofstop_lonfrom the first row of data (i.e., the second row in the file!)Use a
forloop to go over the rows of'stops.txt'. Inside theforloop, use a conditional to check whether thestop_lonvalue from the current row in'stops.txt'is smaller than the current value ofxmin. If it is, replacexminwith thestop_lonvalue. If it is not, do nothing.When the loop ends,
xminshould contain the minimal value from thestop_loncolumn in'stops.txt'Once your code works properly for
xmin, expand it to do the same for the other three variables (ymin,xmax, andymax) to hold the values \(lat_{min}\), \(lon_{max}\), and \(lat_{max}\), respectively. Make sure you use the right type of conditional (smaller/larger) and the right variable (stop_lon/stop_lat) when calculating each variable.Finally, collect the four values (
xmin,ymin,xmax, andymax) into alistof the form[xmin, ymin, xmax, ymax]
The range function#
The range function is used to generate a sequence of values, given:
start—Start value (inclusive), default is0stop—Stop value (exclusive)step—Step size, default is1
If just one value is given, then it is passed to stop. Namely, range(stop) is equivalent to range(0,stop,1).
The range function is commonly used with for loops (see for loops), to iterate over a sequence of numbers. For example:
for i in range(5):
print(i)
0
1
2
3
4
The range function returns a special kind of object which can be thought of as a “lazy sequence”. It is “lazy” in the sense that it does not compute all values at once, but only one at a time, on demand, which is a more memory-efficient approach:
range(5)
range(0, 5)
To “force” the generation of all values at once, we can wrap the range object inside list:
list(range(5))
[0, 1, 2, 3, 4]
Exercise 03-e
Which expression do we need to use to get a sequence of all even numbers between
0and30, i.e.,0,2, …,30?
Note
When working with Python loops and iteration, you will eventually encounter the technical terms iterable, iterator, and generator. The definitions and distinction can be confusing, so here is a short summary. The terms are hereby ordered from most general to most specific:
An iterable is any object that can be iterated, such as in a
forloop. For example, alistis iterable, therefore if we have a listxwe can usefor i in x:to iterate on all elementsiofx.An iterator is an object that represents a stream of data, which we can go over, each time getting the next element using
next. Iterators are also iterable, meaning that you can over them in a loop, but they are stateful (e.g., they remember which item was obtained usingnext), meaning that you can go over them just once. For example, file reader objects, such as the ones created withcsv.DictReader(see Reading CSV files), are iterators.A generator is a function that returns an iterator. For example,
csv.DictReaderis a generator. Therasteriopackages extensively uses generators, as we will see later on (see Using rasterio and The rasterio.features.shapes function)
For a discussion about the difference between iterable, iterator, and generator, check out the following threads:
List comprehension#
Often, we are interested in creating a list that contains results coming from a for loop operating on another list. For example, suppose that we have a list named x:
x = [5, 7, 10, -2]
and we need to produce a new list named y where each element of x is multiplied by 2. Using the ordinary for loop methods (see for loops), here is how it can be done:
y = []
for i in x:
y.append(i*2)
y
[10, 14, 20, -4]
Python has a convenient and commonly used shortcut to do just that, known as list comprehension. Using list comprehension, here is how we can do the same task:
y = [i*2 for i in x]
y
[10, 14, 20, -4]
The syntax and concept are fairly similar to an ordinary for loop, just more concise. For each element i in x, we calculate i*2. The enclosing brackets indicate that the results are collected into a new list.
Defining functions#
Function definition#
Defining a function is the basic mechanism to minimize code repetition in programming. When you are doing the same task repetitively, e.g., in different parts of the same script, or in different scripts, it does not makes sense to type the same code several times. Instead, you can define a function in one place, then call the function anywhere you need.
The structure of a function definition in Python is as follows:
def function_name(parameter1, parameter2, ...):
expression1
expression2
...
return value
Note the following components:
The function is initialized using the
defkeyword.Next comes the function name (e.g.,
function_name), of our choice, followed by zero or more parameters in parentheses (e.g.,parameter1andparameter2) separated by commas.Finally, we have an indented code block which is the body of the function.
Inside the code block, we may have one or more
returnstatements which terminate the function and return the specifiedvalue.
The code block is where we define what the function does. In zero or more places in the code block we may insert the return keyword, followed by a value that the function should return (e.g., value). When the interpreter reaches a return statement, the function terminates. Without any return statements, the function returns None (see None (None)).
For example, the following code section defines a function named divide, which has two parameters a and b. The function divides a by b and returns the result:
def divide(a, b):
return a / b
Once the function is defined, we can call the function to actually use it. If the function has any parameters, then we need to specify them as part of the function call, in parentheses (unless they are associated with default values, see below Default arguments). The specified values are called arguments. For example, the following function call executes divide, with the arguments 10 and 4. The returned value is 2.5:
divide(10, 4)
2.5
The latter argument specification is known as positional arguments, because the arguments are matched with the parameters by position:
10is matched with the first parametera4is matched with the second parameterb
Using a different order of positional arguments will result in a different matching:
divide(4, 10)
0.4
We can also specify the matching between arguments and parameters “manually”, which is known as keyword arguments. In this case, any order of arguments can be used:
divide(a=10, b=4)
2.5
divide(b=4, a=10)
2.5
Local vs. global variables#
It is important to understand the distinction between local and global variables. Any variable that is defined as part of the function code block (such as a and b, above) is local to that function. This means that it is not accessible in the global environment. You can try printing the value of a or b, resulting in a “not defined” error.
Conversely, global variables, that is, variables defined in the main part of the script outside of any function, are accessible anywhere, including in functions. However, using global variables inside a function is considered bad practice, because it makes the function dependent on the global context rather than self-contained.
Default arguments#
Default arguments, if any, are specified as part of the function definition. For example, here is how we can set the default argument of 2 for parameter b:
def divide(a, b=2):
return a / b
Any arguments explicitly specified as part of the function call override the defaults:
divide(10, 4)
2.5
When an argument is unspecified in the function call, the default value is used. For example, divide(10) is equivalent divide(10,2):
divide(10)
5.0
Exercise 03-f
Write a function named
circle_areathat accepts a radius and returns the circle area (\(A=πr²\)).You can use the built-in variable
math.pifor the value of \(π\). Formath.pito be available, first import themathpackage usingimport math(see Loading packages).Test your function by calling it with a specific value. For example,
circle_area(5)should return78.53982.
Variable-length positional arguments#
A special type of parameter, marking positional (i.e., unnamed) arguments of unknown length, can be specified with an asterisk. Conventionally, the variable-length positional parameter is named *args (short for “arguments”), though you can use any name, such as *x. This special parameter “collects” all arguments passed to the function into a tuple (see Tuples (tuple)). Using *args is most useful when the number of arguments that the function needs to accept is unknown in advance (such as a function that concatenates its inputs).
For example, the following function accepts positional arguments *args, and just returns them without doing anything:
def f(*args):
return args
When calling the function with any number of arguments, we can see that they are accessible inside the function body through the args local variable:
f(1, 4)
(1, 4)
f(1, 4, 'a')
(1, 4, 'a')
f(1, 4, 'a', 3)
(1, 4, 'a', 3)
Exercise 03-g
Write a function named
pastethat:accepts any number of strings, integers, or floats, and
combines them into one long string and returns it.
For example:
paste('Hello','World')should return'HelloWorld'paste('A','B','C',1,2,3)should return'ABC123'
Use variable-length positional arguments (
*args) to make the function work with any number of inputs.
The variable-length positional arguments technique also works the other way around. Namely, when we pass a list or tuple preceded by an asterisk (*) to a function, as in f(*args) where args is a list or a tuple, the elements are interpreted as separate arguments.
For example, suppose that we have a function named f with four arguments:
def f(a, b, c, d):
print(a, b, c, d)
When called in the usual way, we need to specify the four arguments, separately:
f(1, 2, 3, 4)
1 2 3 4
However, if we already have the arguments in a list, we can pass the list as-is, so that list elements are “mapped” to arguments a, b, c, d:
x = [1, 2, 3, 4]
f(*x)
1 2 3 4
which is equivalent to:
f(x[0], x[1], x[2], x[3])
1 2 3 4
For example, we are going too use positional arguments when passing arguments to the shapely.box function (see Bounds (shapely), Raster extent).
Variable-length keyword arguments#
Variable-length keyword arguments are similar in concept to their positional counterpart (Variable-length positional arguments), as both are used to pass an unknown number of arguments to a function. The difference is that variable-length keyword arguments need to be named. Accordingly, they are accessible inside the function as a dict (see Dictionaries (dict)), rather than a tuple. Keyword arguments are most useful when we need to flexibly pass named arguments, without restricting their number and their names in the function definition. Variable-length keyword arguments are marked with two asterisks, conventionally named **kwargs (short for “keyword arguments”), though you can use a different name.
For example, the following definition of the function f accepts keyword arguments:
def f(**kwargs):
return kwargs
The function now accepts variable-length keyword arguments, which are collected into a dict named kwargs:
f(x=1, y=4)
{'x': 1, 'y': 4}
f(x=1, y=4, z='a')
{'x': 1, 'y': 4, 'z': 'a'}
f(x=1, y=4, z='a', abc=3)
{'x': 1, 'y': 4, 'z': 'a', 'abc': 3}
Keyword arguments can also be used the other way around. Namely, the f(**kwargs) function calls, where kwargs is a dictionary, is translated into f(key1=value1,key2=value2,...) for all key/value pairs in kwargs.
We are going to see an example of this technique later on, when using the rasterio.open function (see Stacking raster bands).
Lambda functions#
Other than the ordinary def syntax for defining a function (see Function definition), Python has another method to define functions called lambda expressions. Here is how it looks like:
divide = lambda a, b: a / b
divide(10, 4)
2.5
Note the structure of the lambda function definition:
lambda parameter1, parameter2, ...: expression
Importantly, the function parameters come after the lambda keyword. Then, after a colon, there is a single expression. The result of the expression is returned by the function.
A lambda function can be assigned to a variable, such as divide in the above example. That way, the only advantage over the “ordinary” syntax (see Function definition), in situations when the function consists of a single expression, is slightly shorter code. However, another advantage of lambda functions is that they can be used immediately, witout assigning to a variable, which is known as an “anonymous” function. For example:
(lambda a, b: a / b)(10, 4)
2.5
The most useful feature of anonymous function is that we can pass them as arguments to other functions, without needing to define a function in a separate expression. This will become clear later on, when we encounter situations where we pass a function as an argument to another function (see apply and custom functions and Custom functions (agg)).
Example: distance function#
Here is an example of a more complex function definition, modified from a StackOverflow answer. The function, named distance,
accepts two lists, or tuples, of the form
(lon,lat), andreturns the distance between them, in meters.
The distance function uses a distance approximation method known as the Harvesine formula. Here is the function definition:
import math
def distance(pnt1, pnt2):
lon1, lat1 = pnt1
lon2, lat2 = pnt2
radius = 6371000
dlat = math.radians(lat2 - lat1)
dlon = math.radians(lon2 - lon1)
a = (math.sin(dlat / 2) * math.sin(dlat / 2) +
math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) *
math.sin(dlon / 2) * math.sin(dlon / 2))
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
d = radius * c
return d
We are not going to get into the mathematical details of the distance calculation according to the Harvesine formula. However, note the general structure of the function, most importantly:
the first line
def distance(origin,destination):which specifies the function name and the list of parameters, andthe last line
return dwhich returns the result.
Also note the expression import math, right before the function definition. Importing the standard math package is required since the distance function code uses several mathematical functions, namely math.radians, math.sin, math.cos, math.atan2, and math.sqrt.
Once the distance function is defined, we can call it with specific arguments, to calculate the approximate distance (in meters) between any given points. For example, the distance between two points separated be one decimal degree on the equator is 111.2 km:
distance((0, 0), (1, 0))
111194.92664455874
The distance between two points separated be one decimal degree on latitude of 80 degrees, however, is only 19.3 km:
distance((0, 80), (1, 80))
19308.558693383016
Exercise 03-h
How can the above function be modified to return the rounded distance in meters? Modify the function code and try running the modified version to make sure it works.
More exercises#
Exercise 03-i
Find the row that represents the southernmost bus station in Israel, i.e., the one that has the minimal value in the
stop_latcolumn, according to the filestops.txt.Hint: initialize two variables, one to store the currently southernmost row, and one to store the currently minimal latitude (initialized with the latitude of the first stop in the file). Then, as part of the loop that goes over the remaining rows, use a conditional to check whether the current latitude is smaller than the minimal one. If it is, replace the current southernmost row with the current row, and replace the currently minimal latitude with the current latitude.
What kind of change do you need to make in your code to calcualate the nothernmost bus station instead?
Exercise 03-j
Count the number of cities in each “quadrat” of the world, according the the table of world cities coordinates in the file
world_cities.csv. The table contains a list of all major world cities, with city coordinate values in thelong(longitude) andlat(latitude) columns.Quadrats are defined as follows:
North-East:
long>0andlat>0North-West:
long<0andlat>0South-East:
long>0andlat<0South-West:
long<0andlat<0
Store the results in a dictionary and print it.
Exercise solutions#
Exercise 03-a#
lunch = [
'Salad',
'Salad',
'Egg',
'Beef',
'Potato',
'Tea',
'Potato',
'Potato',
'Coffee'
]
result = {}
for i in lunch:
if i in result:
result[i] += 1
else:
result[i] = 1
result
{'Salad': 2, 'Egg': 1, 'Beef': 1, 'Potato': 3, 'Tea': 1, 'Coffee': 1}
Exercise 03-c#
import csv
count = 0
f = open('data/gtfs/stops.txt', 'r', encoding='utf-8-sig')
reader = csv.DictReader(f)
for row in reader:
count += 1
f.close()
count
34007
Exercise 03-d#
import csv
f = open('data/gtfs/stops.txt', 'r', encoding='utf-8-sig')
reader = csv.DictReader(f)
row = next(reader)
xmin = float(row['stop_lon'])
xmax = float(row['stop_lon'])
ymin = float(row['stop_lat'])
ymax = float(row['stop_lon'])
for row in reader:
row['stop_lon'] = float(row['stop_lon'])
row['stop_lat'] = float(row['stop_lat'])
if row['stop_lon'] < xmin:
xmin = row['stop_lon']
if row['stop_lon'] > xmax:
xmax = row['stop_lon']
if row['stop_lat'] < ymin:
ymin = row['stop_lat']
if row['stop_lat'] > ymax:
ymax = row['stop_lat']
f.close()
bounds = [xmin, ymin, xmax, ymax]
bounds
[34.284672, 29.492446, 35.839108, 34.917554]
Exercise 03-g#
paste('Hello', 'World')
'HelloWorld'
paste('A', 'B', 'C', 1, 2, 3)
'ABC123'
Exercise 03-i#
{'stop_id': '12510',
'stop_code': '10615',
'stop_name': 'מעבר גבול טאבה',
'stop_desc': 'רחוב: דרך מצרים 168 עיר: אילת רציף: קומה: ',
'stop_lat': '29.492446',
'stop_lon': '34.904605',
'location_type': '0',
'parent_station': '',
'zone_id': '10615'}
Exercise 03-j#
import csv
result = {'ne': 0, 'nw': 0, 'se': 0, 'sw': 0}
f = open('data/world_cities.csv', 'r', encoding='utf-8')
reader = csv.DictReader(f)
for row in reader:
lon = float(row['lon'])
lat = float(row['lat'])
if(lon > 0 and lat > 0):
result['ne'] += 1
if(lon < 0 and lat > 0):
result['nw'] += 1
if(lon > 0 and lat < 0):
result['se'] += 1
if(lon < 0 and lat < 0):
result['sw'] += 1
f.close()
result
{'ne': 28485, 'nw': 10026, 'se': 2689, 'sw': 2445}