Chapter 9 Geometric operations with rasters
Last updated: 2025-02-06 09:30:30
Aims
Our aims in this chapter are:
- Make changes in the geometric component of rasters:
- Mosaicking
- Resampling
- Reprojecting
- Apply focal filters on a raster
We will use the following R packages:
starsunits
9.1 Mosaicking rasters
In the next few examples, we will prepare a Digital Elevation Model (DEM) raster of Haifa, by mosaicking, subsetting and reprojecting (Section 9.3).
We start with two \(5°\times5°\) tiles of elevation data from the Shuttle Radar Topography Mission (SRTM) dataset. The tiles are included as two .tif files in the sample files (Appendix A):
As shown in Figure 9.1, the tiles cover the area of northern Israel, including Haifa:
plot(dem1, breaks = "equal", col = terrain.colors(10), axes = TRUE)
## downsample set to 5
plot(dem2, breaks = "equal", col = terrain.colors(10), axes = TRUE)
## downsample set to 5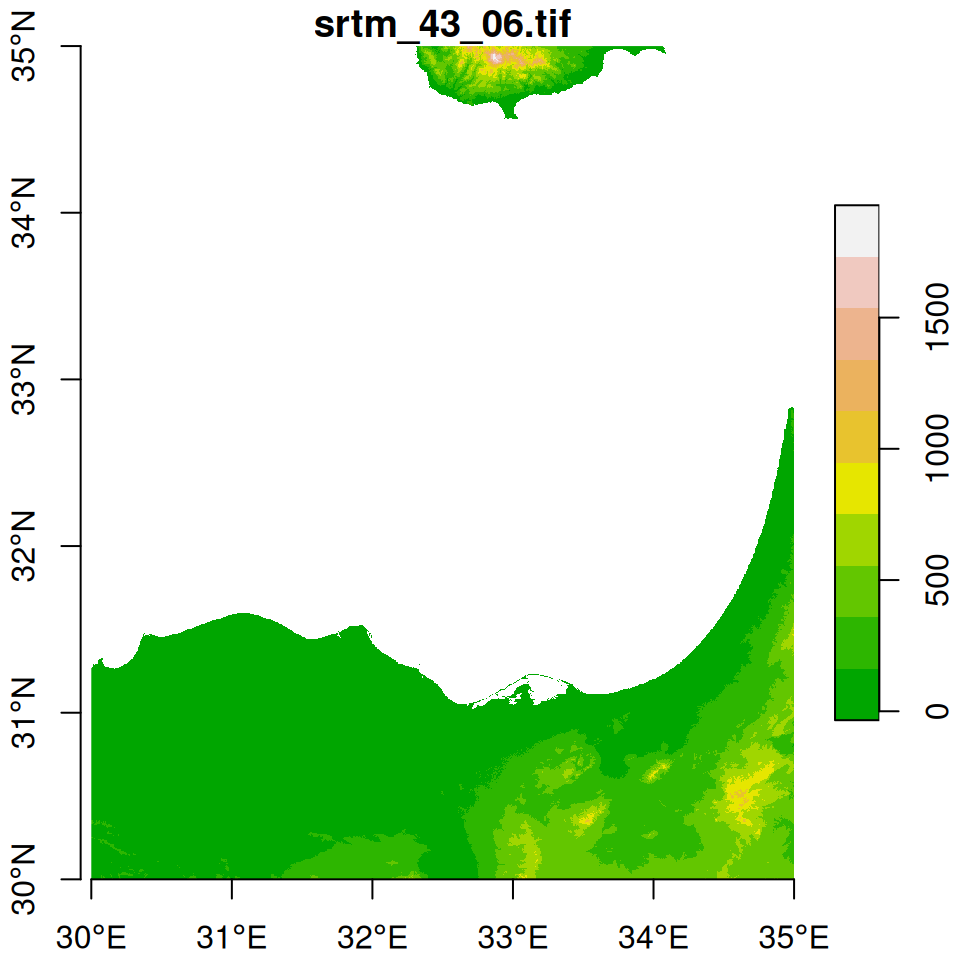
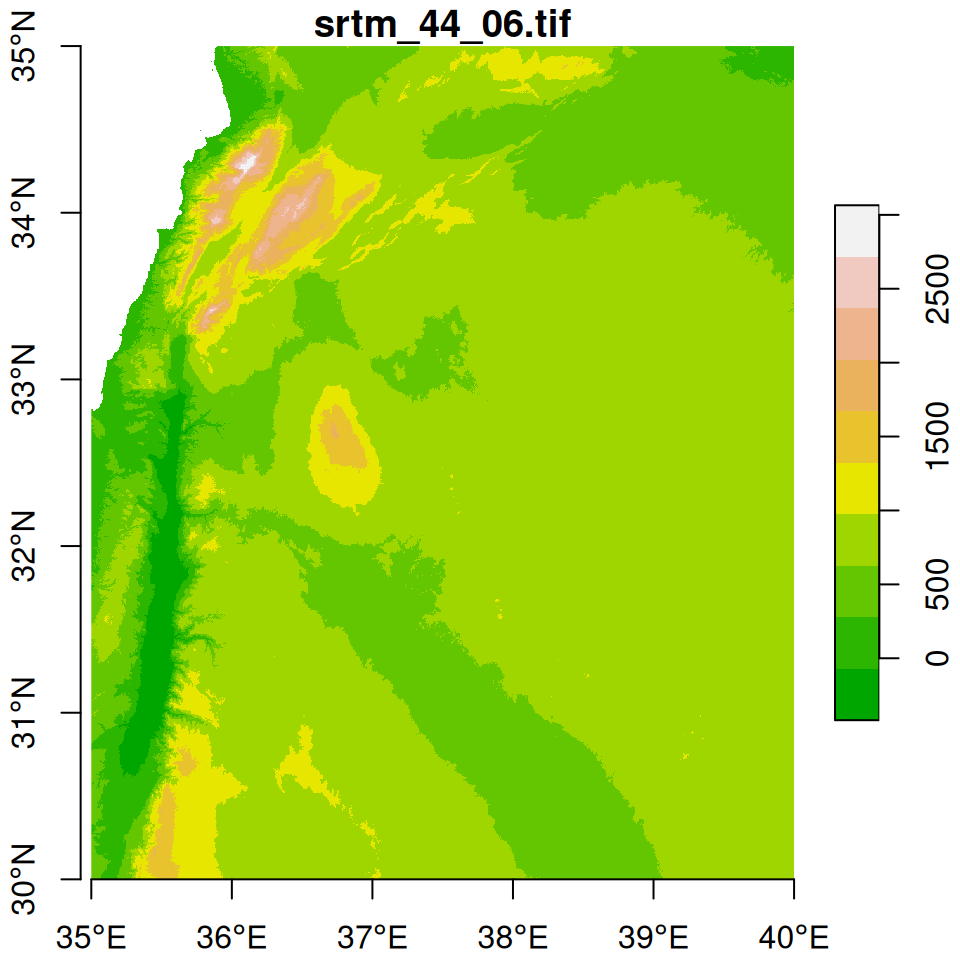
Figure 9.1: Two elevation tiles from the SRTM dataset
Using the st_bbox and dim functions (Section 5.3.8.3), we can see that the two rasters indeed comprise two tiles of the same “large” dataset. First, we can see that the dimensions (number of rows and columns) of the two rasters are identical:
Second, we can see that their extents are aligned. The y-axis (i.e., latitude) extent of the rasters is the same (30-35). The x-axis (i.e., longitude) extents of the rasters are side-by-side (30-35 and 35-40):
Raster datasets with global coverage (or other large areas) are commonly distributed in the form of tiles. While tile dimensions and placement may differ in each case, the general idea of tiling is the same: reducing the amount of data that the user needs to deal with. Rather than have the user download a huge (e.g., global) raster file and crop their area of interest, which can be challenging and time-consuming due the file size, the user can download only the required tiles, mosaic them, and then crop the specific area of interest. That way, the user doesn’t have to download and deal with huge files where most of the data are irrelevant.
Rasters can be mosaicked using the st_mosaic function. The st_mosaic function accepts two or more stars objects—such as dem1 and dem2—and returns a combined raster:
Note that the st_mosaic function can be used to combine rasters even if they are not aligned (unlike dem1 and dem2, in this example, which are aligned). In case the rasters are not aligned, resampling (Section 9.2) takes place.
The mosaicked DEM is shown in Figure 9.2:
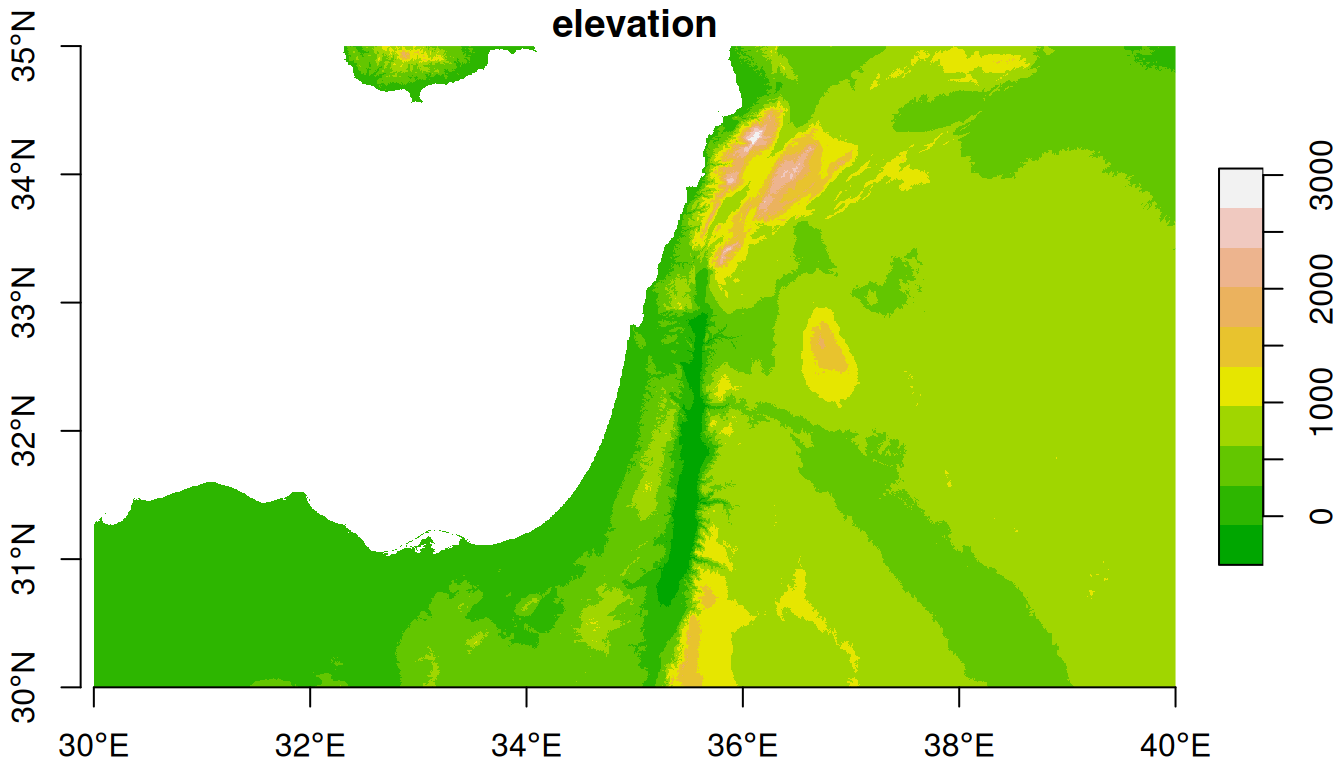
Figure 9.2: Mosaicked raster
The extent of the resulting raster covers the extents of both inputs:
For the next examples, we “crop” the dem raster according to an extent of \(0.25°\times0.25°\) around Haifa (Figure 9.3).
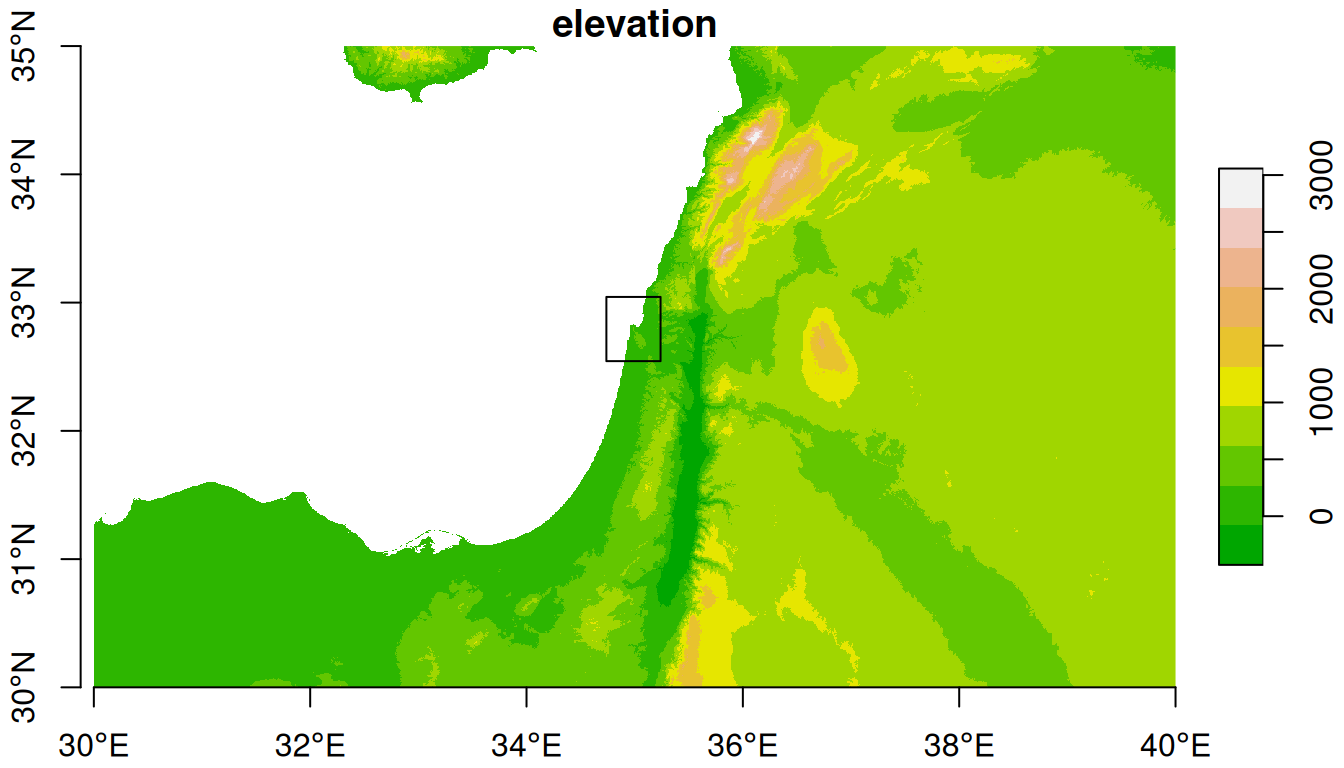
Figure 9.3: An \(0.25°\times0.25°\) rectangular extent
The [ operator can be used to crop the raster (Section 6.2):
The result is shown in Figure 9.4:
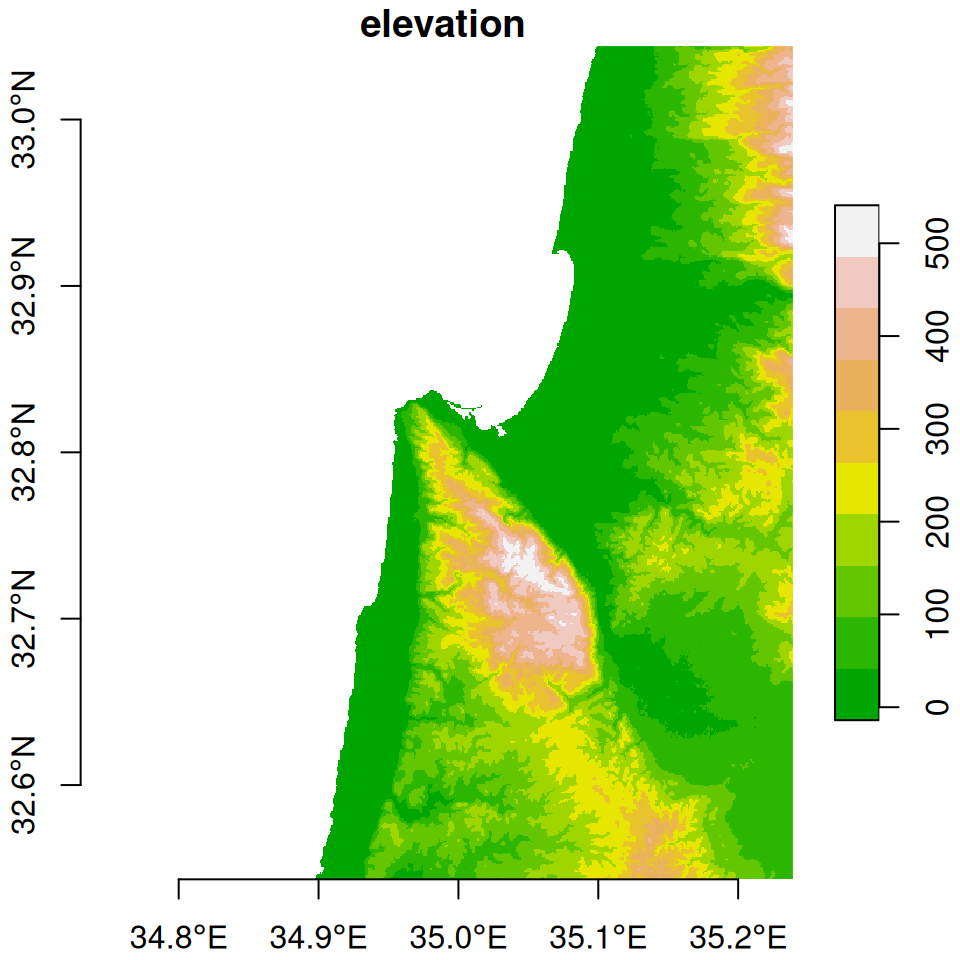
Figure 9.4: Cropped raster
Note that in this example, we needed to know in advance the row and column indices of the extent we are interested in cropping. Later on (Section 10.1), we are going to learn how to crop a raster based on an existing vector layer, which is more practical.
9.2 Raster resampling
9.2.1 The st_warp function
Raster resampling is the process of transferring raster values from the original grid to a different grid (Figure 9.5). Resampling is often required for:
- Aligning several input rasters that come from different sources to the same grid, so that they can be subject to spatial operators such as raster algebra (Sections 6.4 and 6.6.1)
- Reducing the resolution of very detailed rasters, so that they are more convenient to work with in terms of processing time and memory use
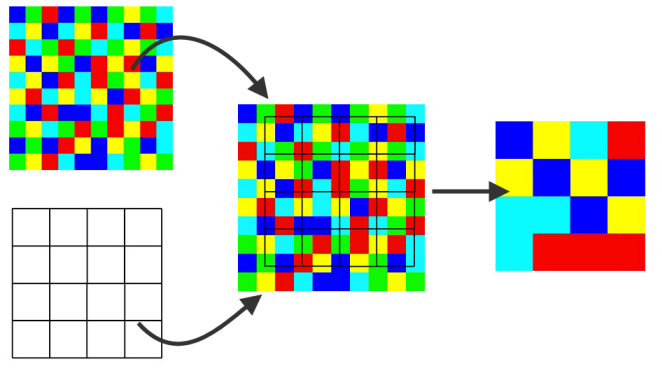
Figure 9.5: Raster resampling (https://www.safe.com/transformers/raster-resampler/)
To demonstrate resampling, we will create a custom stars grid, using the same extent as the dem raster (st_bbox(dem)), but a coarser resolution. The new resolution is \(0.002°\), which is ~2.4 times the original resolution of \(0.00083°\). The grid is created using st_as_stars:
grid = st_as_stars(st_bbox(dem), dx = 0.002)
grid
## stars object with 2 dimensions and 1 attribute
## attribute(s):
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## values 0 0 0 0 0 0
## dimension(s):
## from to offset delta refsys x/y
## x 1 251 34.74 0.002 WGS 84 [x]
## y 1 251 33.04 -0.002 WGS 84 [y]Recall that we already used the st_as_stars function to convert a matrix to a stars raster (Section 6.3.3). What we do here is another mode of operation of the st_as_stars function, creating an empty raster given a bbox and the resolution dx.
We can resample a raster using the st_warp function. The first two parameters of st_warp are:
- The raster to be resampled, where the values come from
- The raster defining the new grid
Here is the expression to resample the values of the dem raster into the new raster grid:
Which one of the rasters in Figure 9.5 represents the role of
demandgrid, in our case?
Try resampling
demto a different grid with an even coarser resulution, such as0.02, and plot the result
The original DEM is shown along with the resampled one in Figure 9.6.
plot(dem, breaks = "equal", col = terrain.colors(10), main = "input (delta=0.0008)", key.pos = 4)
plot(dem1, breaks = "equal", col = terrain.colors(10), main = "output (delta=0.002)", key.pos = 4)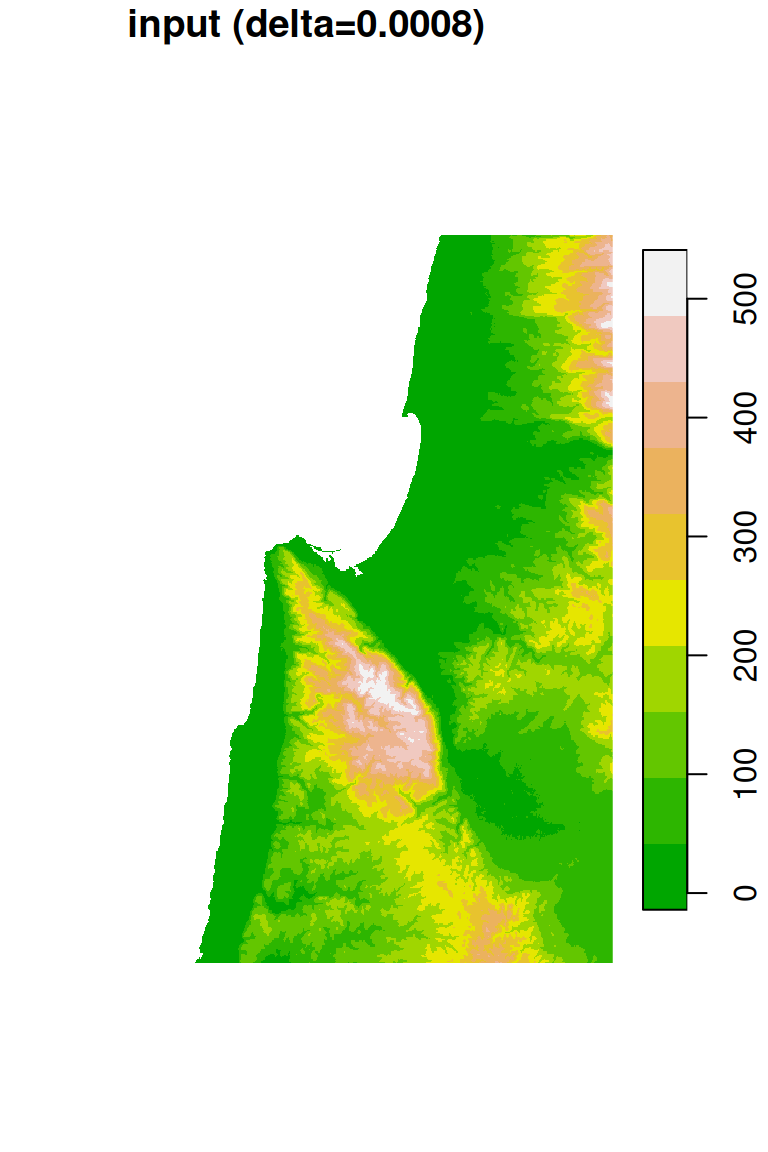
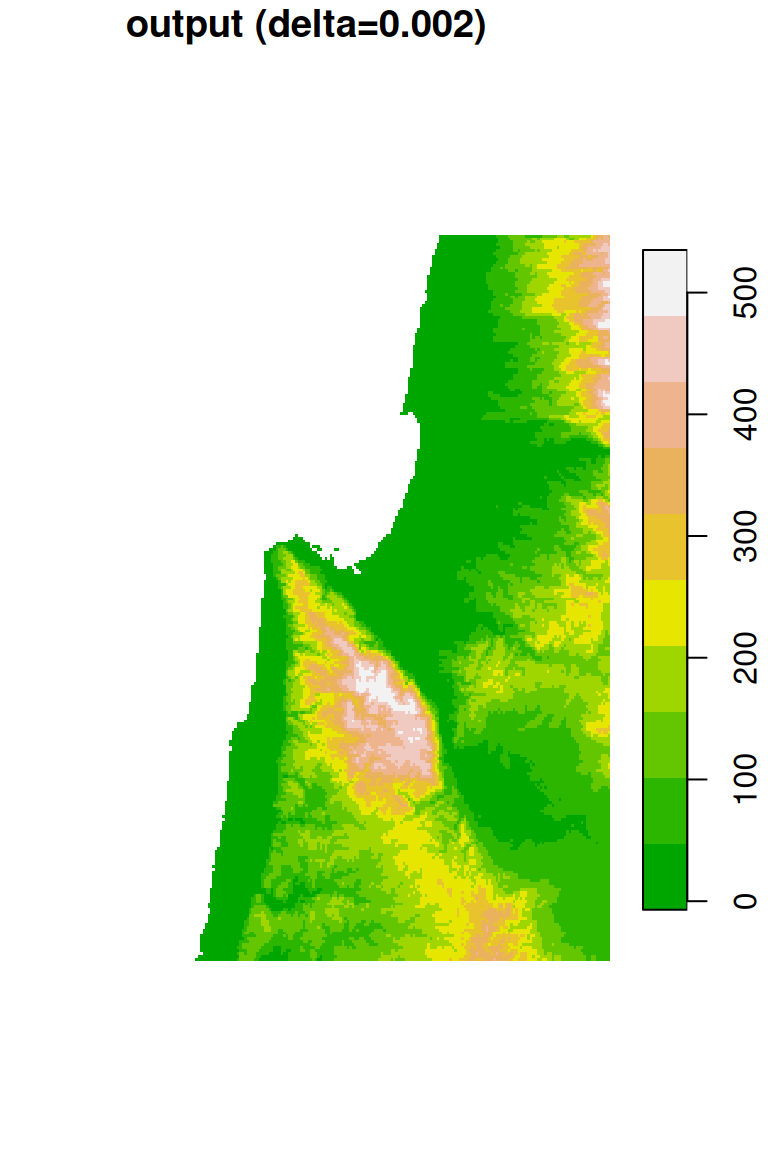
Figure 9.6: DEM resampled by a factor of 2.4, from 0.0008 (left) to 0.002 (right) resolution
When resampling, the computer needs to decide which pixel value(s) to transfer to each of the “new” pixels, defined by the new grid. There are several possible options, known as resampling algorithms, or resampling methods. In the next three sections, we are going to demonstrate three common ones:
9.2.2 Nearest neighbor resampling
The st_warp expression from Section 9.2.1 actually used the nearest neighbor resampling method (method="near"), which is the default:
To understand what actually happens in nearest neighbor resampling, let’s take a look at a small part of the raster “before” and “after” images (Figure 9.7). If you look closely, you can see that the values of the original raster are passed to the resampled raster. What happens when there is more than one pixel of the original raster coinciding with a single pixel in the new grid? How can we decide which value is going to be passed? In nearest neighbor resampling, the new raster pixels get the value from the nearest pixel of the original raster. Note that some of the values may be “lost” this way, since they were not passed on to the new raster34.
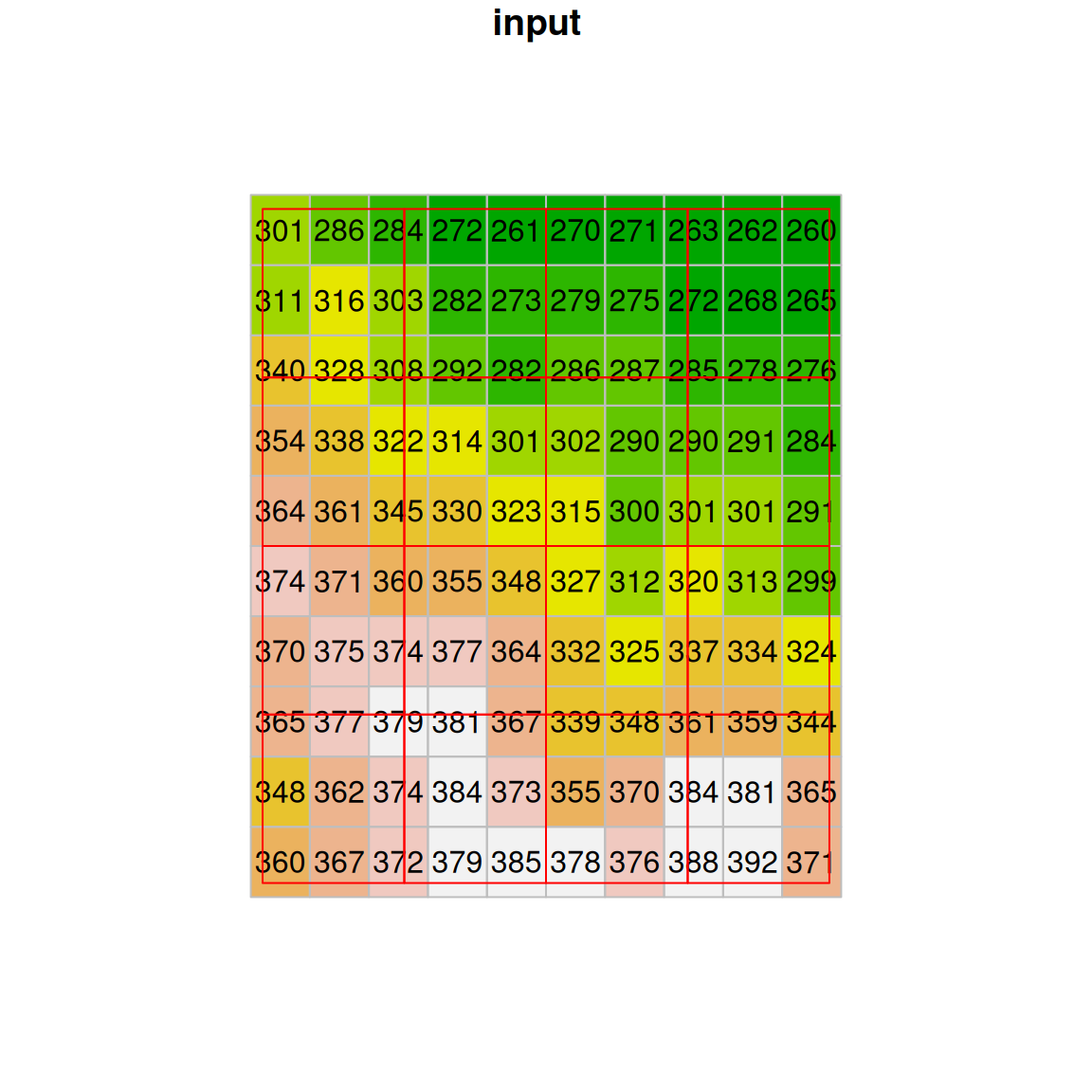
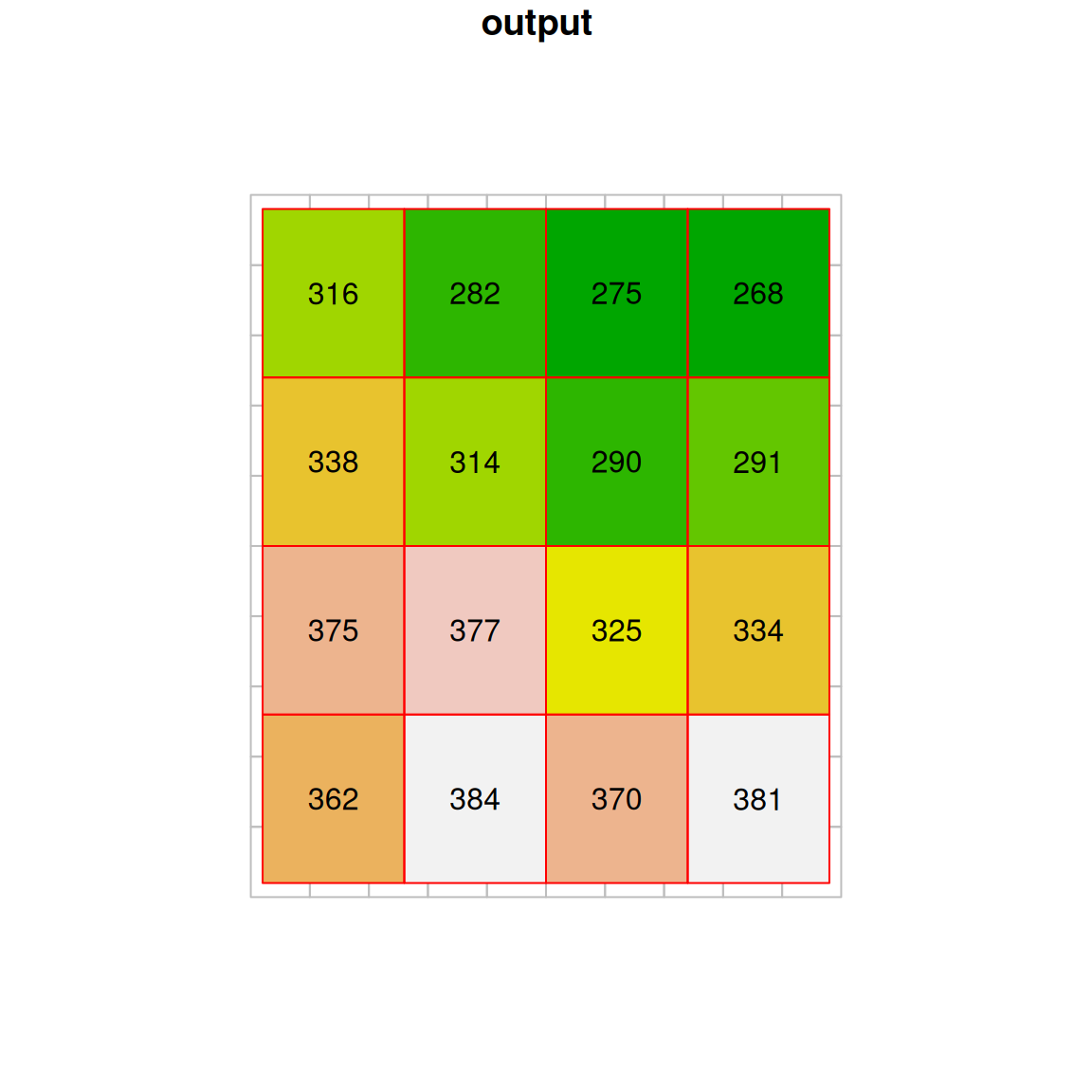
Figure 9.7: Nearest neighbor resampling
9.2.3 Bilinear resampling
Bilinear resampling is another resampling method. In bilinear resampling, each new raster cell gets a weighted average of four nearest cells from the input, rather than just one. Bilinear resampling is specified with method="bilinear" in st_warp. Two technical things to note about st_warp when using a method other than method="near":
use_gdal=TRUEneeds to be specified, otherwise themethodargument is ignoredno_data_valueneeds to be set to a value outside of the valid range (such asno_data_value=-9999for a DEM raster); this has no effect on the final result, however the specified value is used in a temporary raster which is created when using thest_warpfunction
For example:
With bilinear resampling, the output raster is “smoothed”, containing new values which are averages of (some of) the values in the original raster (Figure 9.8).
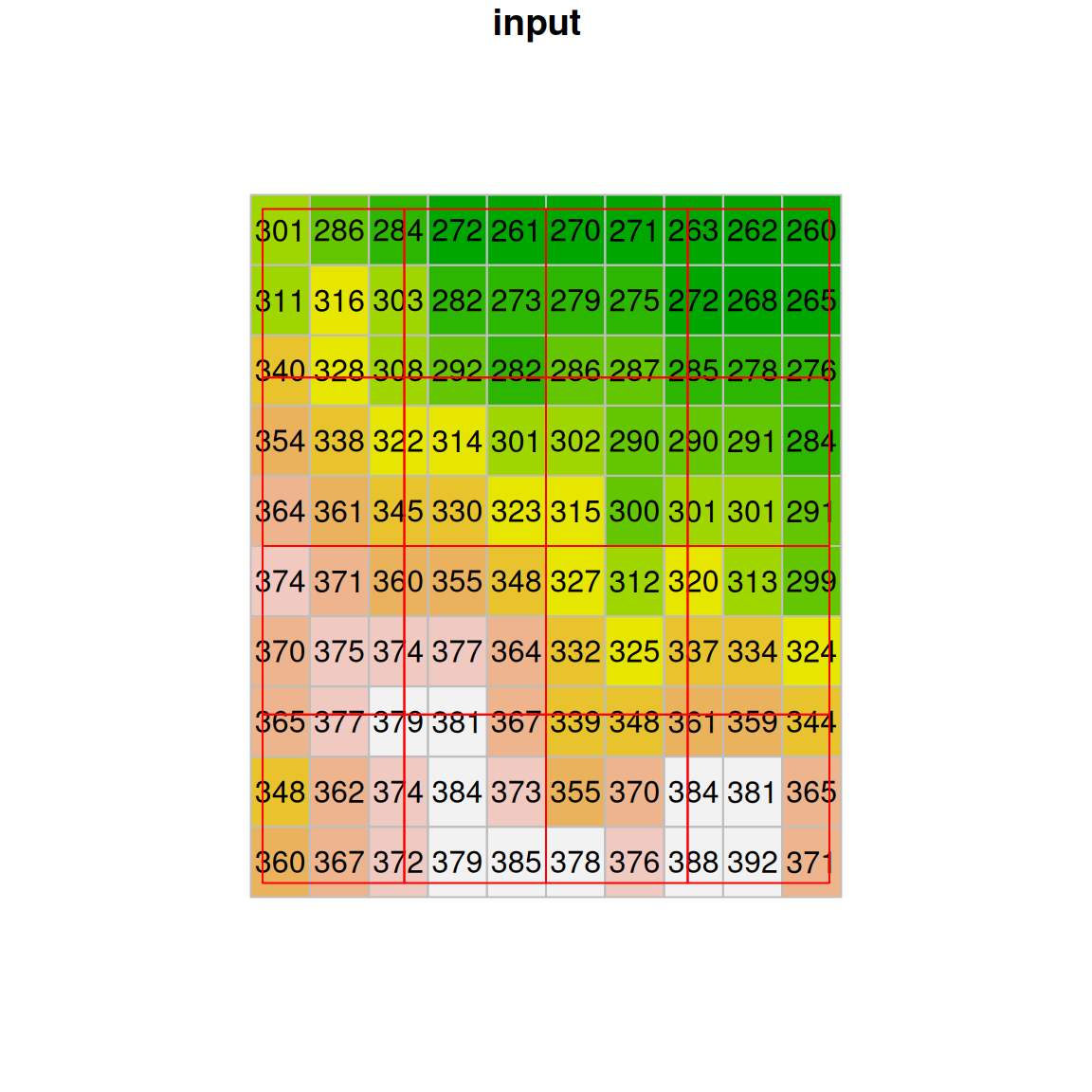
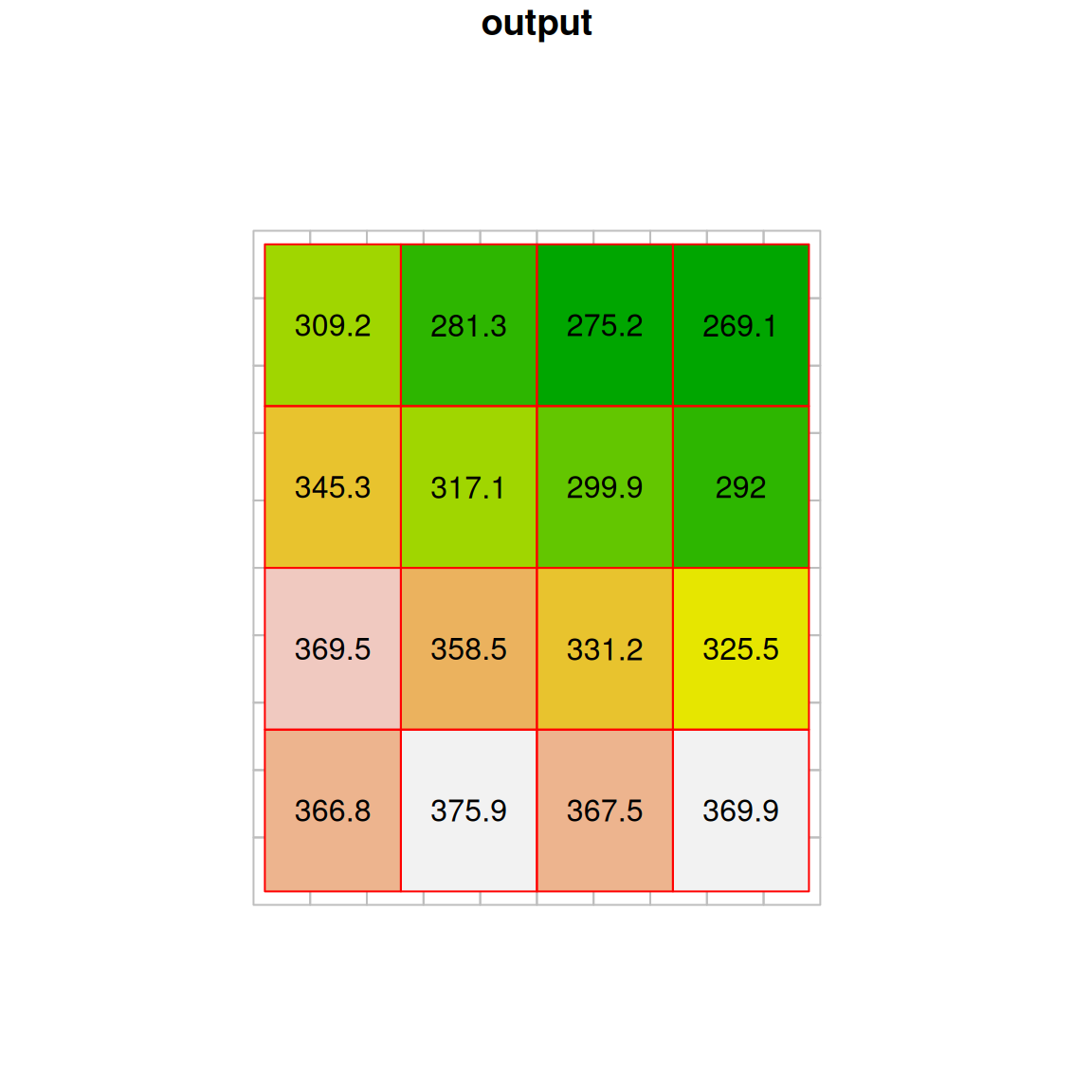
Figure 9.8: Bilinear resampling
9.2.4 Average resampling
Another useful method is the average resampling method, where each new cell gets the average of all overlapping input cells:
The result of average resampling is shown in Figure 9.9:
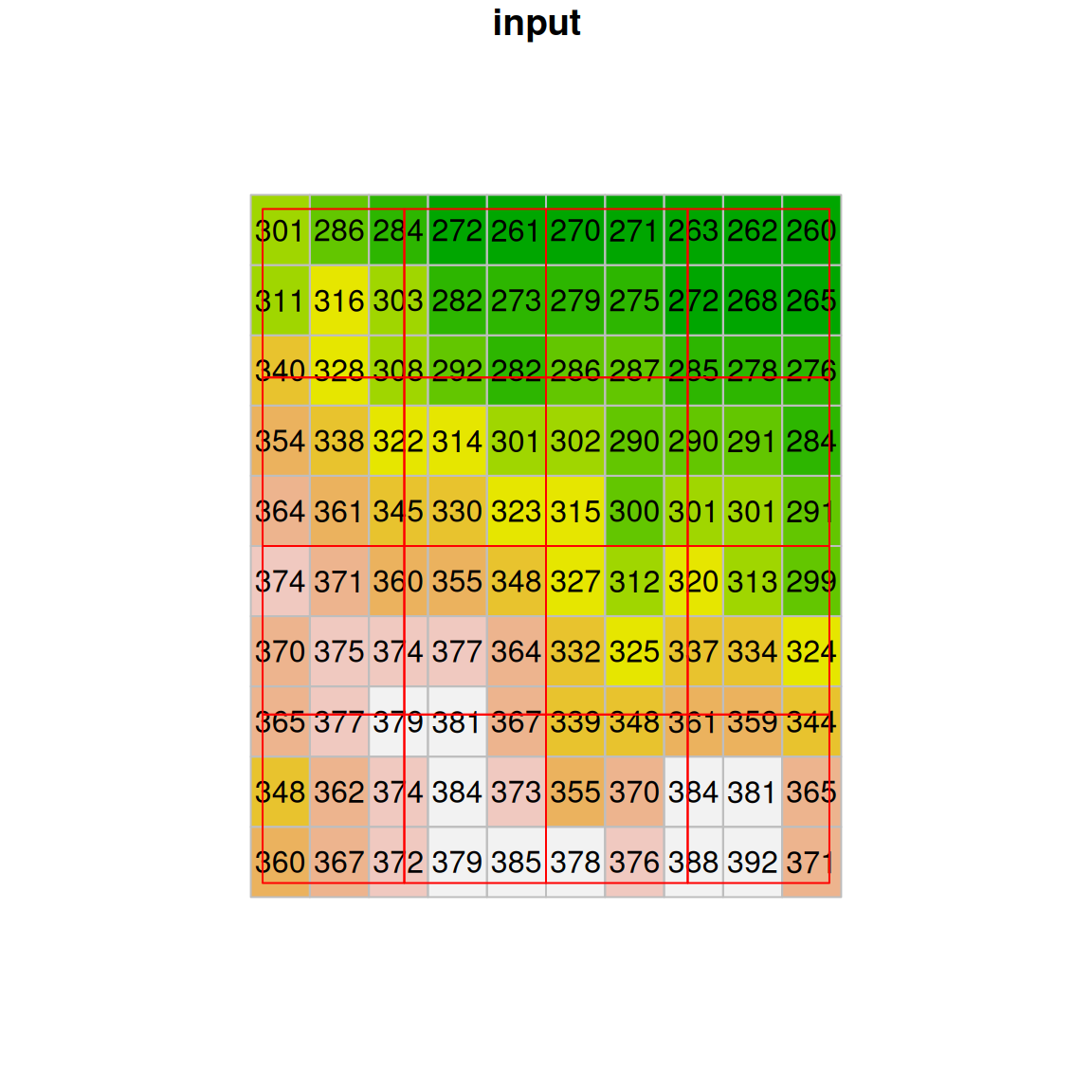
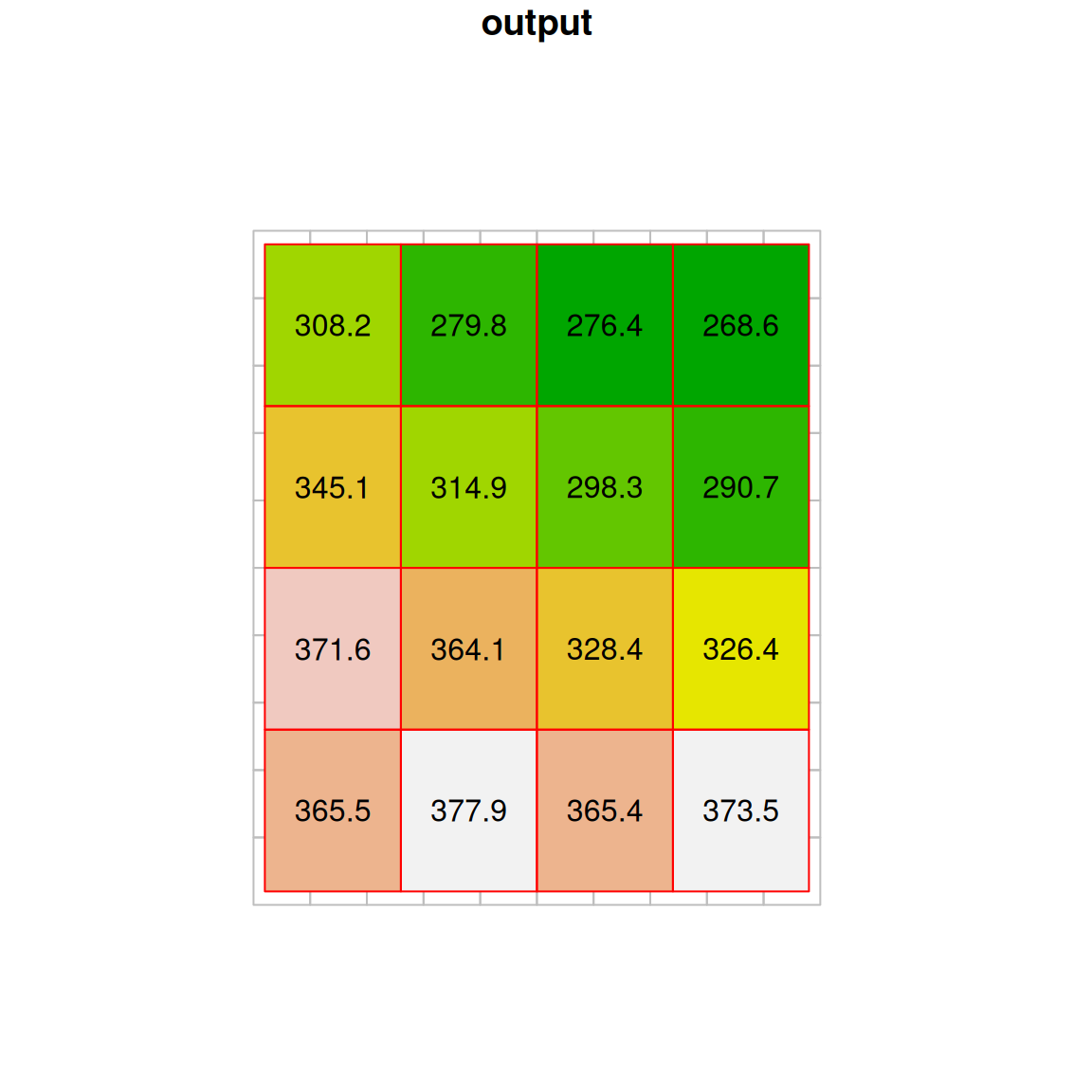
Figure 9.9: Average resampling
In addition to "near", "bilinear", and "average", the st_warp function supports other resampling methods, including: "cubic", "cubicspline", "lanczos", "mode", "max", "min", "med", "q1", and "q3".
Bilinear resampling may be preferred when the result is primarily used for visualization, because the result appears smoother. When using the result for further analysis, however, the original values should be preserved. Generally, either nearest neighbor, mode, or average methods are recommended (Table 9.1), depending on the resolutions of the input and template, and the raster data type. Specifically, keep in mind that when the input raster is categorical, such as a raster with land cover classes 1, 2, 3, etc., nearest neighbor or mode resampling are the only valid methods, while numeric calculations (such as average) on category IDs makes no sense.
| Resolution | Type | Resampling method |
|---|---|---|
| template ≤ input | Categorical / Continuous | Nearest neighbor |
| template > input | Categorical | Mode |
| template > input | Continuous | Average |
9.3 Raster reprojection
Raster reprojection is more complex than vector layer reprojection (Section 7.9.2). In addition to transforming (pixel) coordinates, like in vector layer reprojection, raster reprojection requires a resampling step in order to “arrange” the transformed values back into a regular grid (Figure 9.14).
In terms of code, the st_warp function, which we used for resampling (Section 9.2), is used for raster reprojection too. The only difference is that, in raster reprojection, the destination “grid” is in a different CRS than the input raster.
For example, the following expression reprojects the DEM of Haifa from WGS84 (4326) to UTM (32636), using the nearest neighbor resampling method. Note that, in this example, we are not passing a stars object with the destination grid. Instead, we are letting the function to automatically generate the new grid, only specifying the destination CRS (crs=32636) and resolution (cellsize=90):
The original raster (in WGS84) and the reprojected one (in UTM) are shown in Figure 9.10.
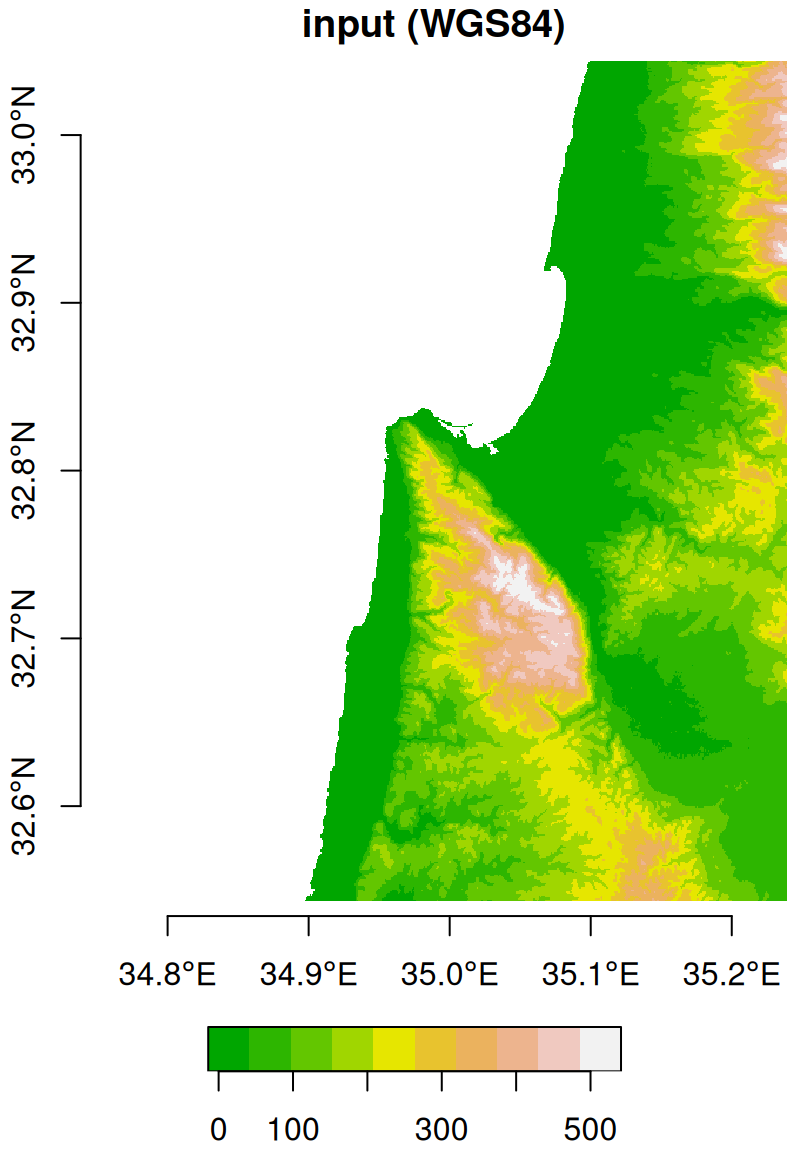
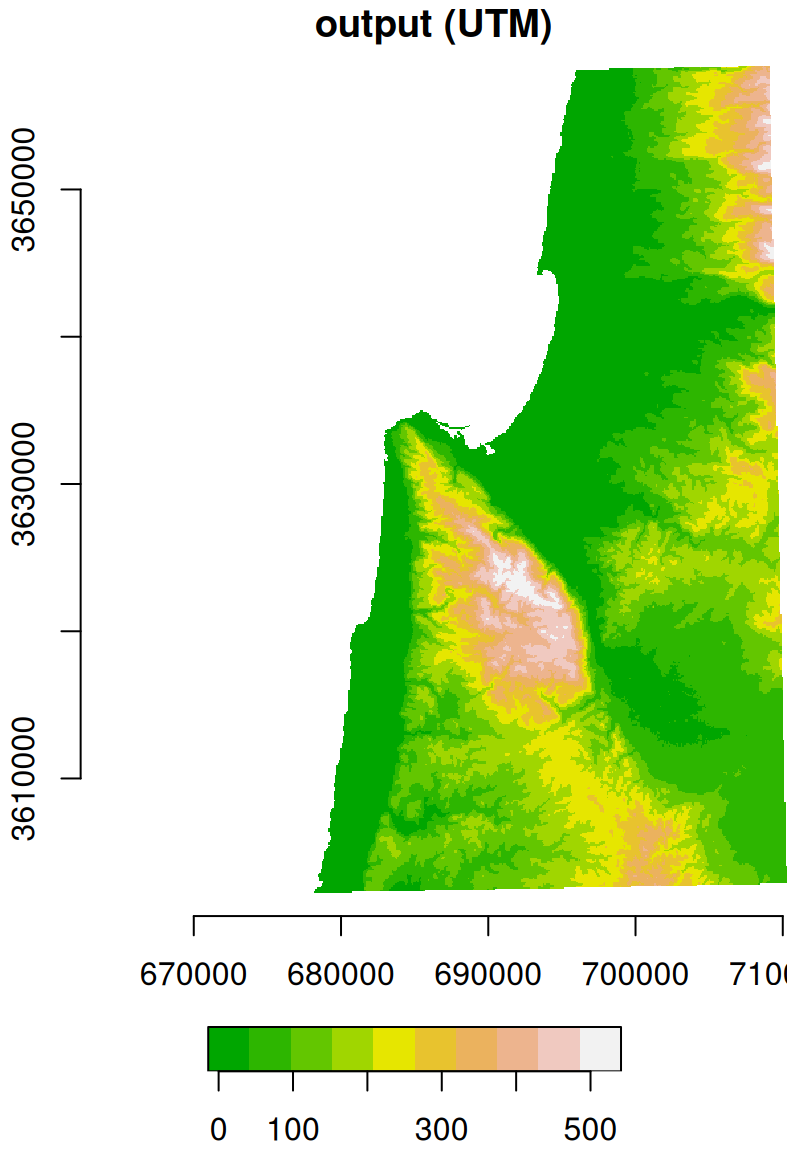
Figure 9.10: Original (left, in WGS84) and reprojected (right, in UTM) dem raster
Note that the coordinate units in the reprojected raster (Figure 9.10) are no longer degrees, but meters. Also, the area contaning non-missing values is slightly rotated compared to the input, because the WGS84 and UTM systems are not parallel, at least in this particular location. A zoomed-in view (Figure 9.11) of the original raster and the new grid demonstrates the latter more clearly. Compare this situation with the previous examples where the destination grid was in the same CRS (Figure 9.7–9.9), therefore the output raster pixels may be shifted, and/or “stretched” or “shrinked” (due to different origins and resolutions, respectively), however they are always parallel to the input pixels.
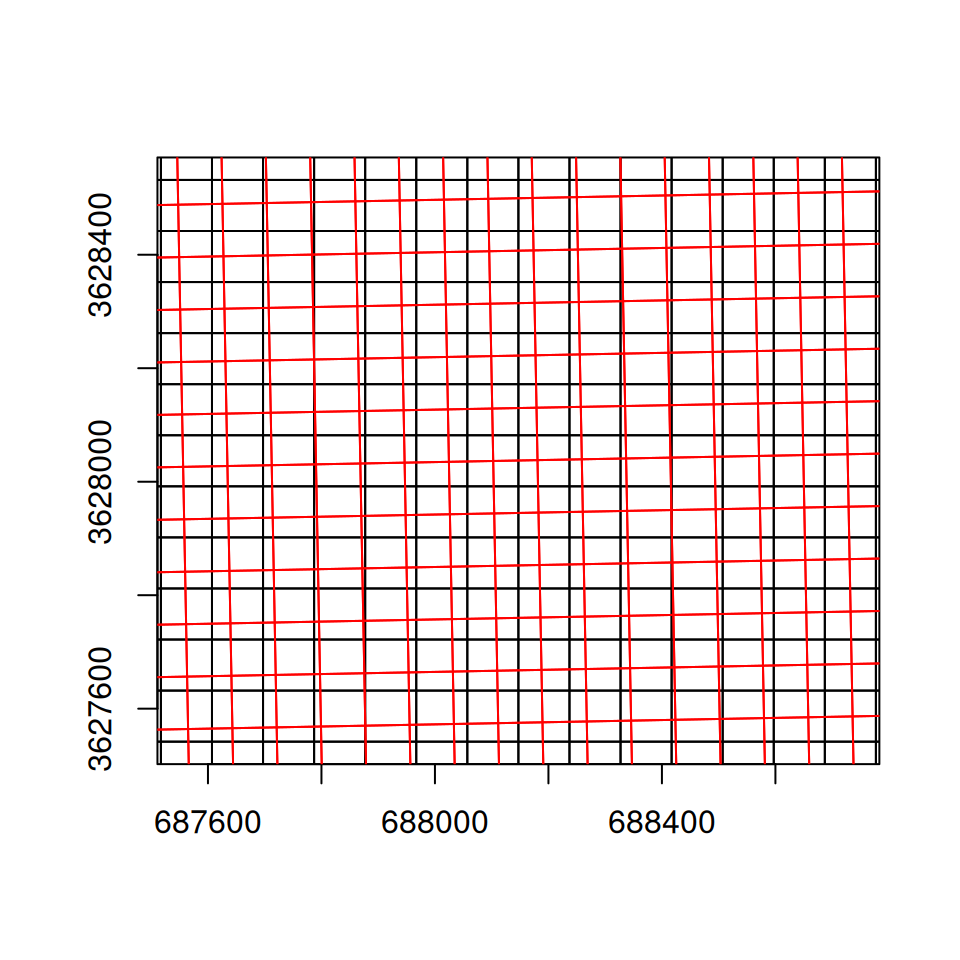
Figure 9.11: The reprojected raster grid (UTM, black) and the original raster grid (WGS84, in red), displayed in UTM
As another example, let’s reproject the MOD13A3_2000_2019.tif, from its rarely used Sinusoidal projection, to a projection more widely used and more suitable for the specific region, such as ITM (Table 7.4). First, let’s import the raster from the GeoTIFF file:
Then, we can reproject the raster using st_warp. This time we specify just the destination CRS (crs=2039), letting the function automatically choose an optimal resolution:
The original and reprojected rasters are shown in Figure 9.12:
plot(r[,,,1,drop=TRUE], key.pos = 4, axes = TRUE, col = hcl.colors(11, "Spectral"), main = "input (Sinusoidal)")
plot(r_itm[,,,1,drop=TRUE], key.pos = 4, axes = TRUE, col = hcl.colors(11, "Spectral"), main = "output (ITM)")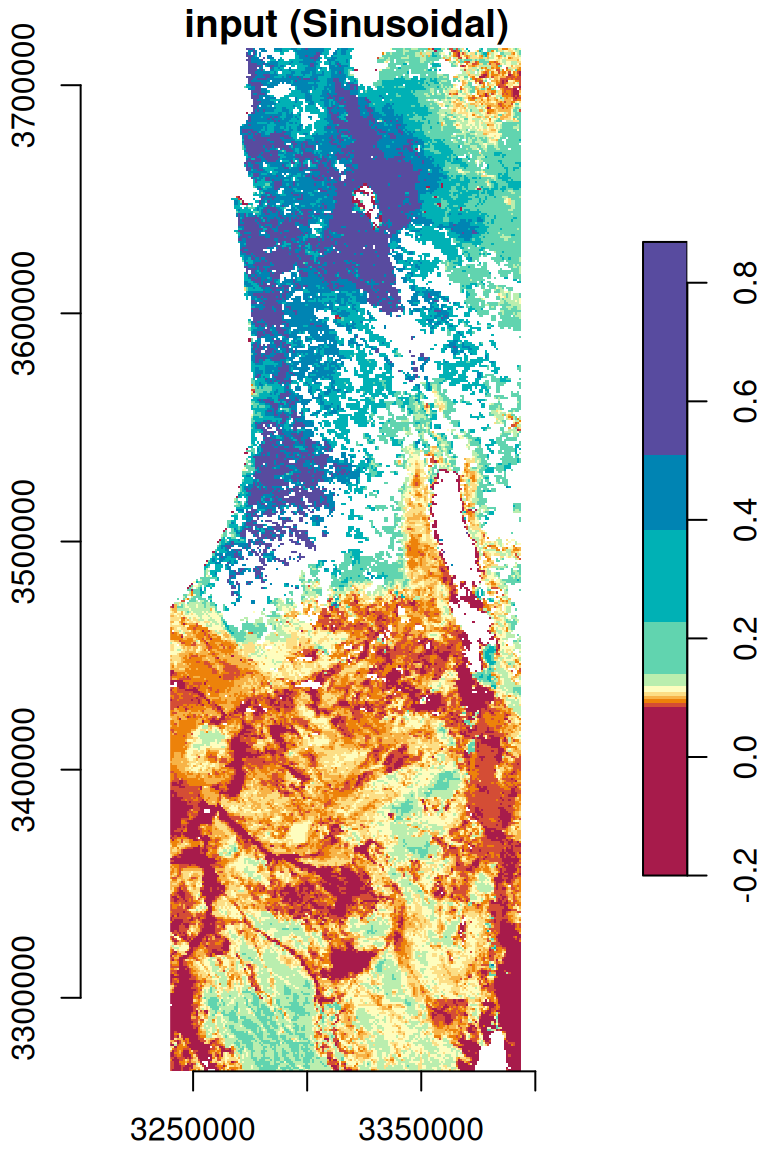
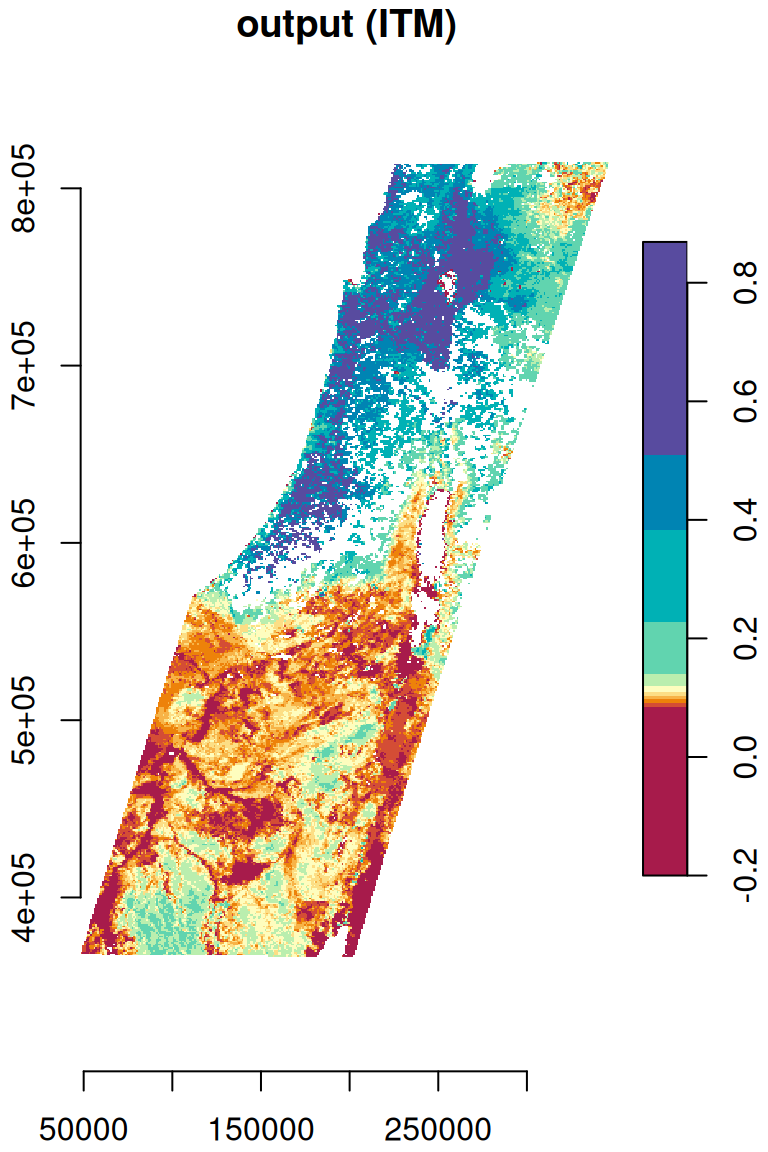
Figure 9.12: Reprojection of the MODIS NDVI raster from Sinusoidal (left) to ITM (right)
To see the process of reprojection more clearly, let’s examine a small subset of the NDVI raster:
The original and reprojected raster subsets are shown in Figure 9.13.
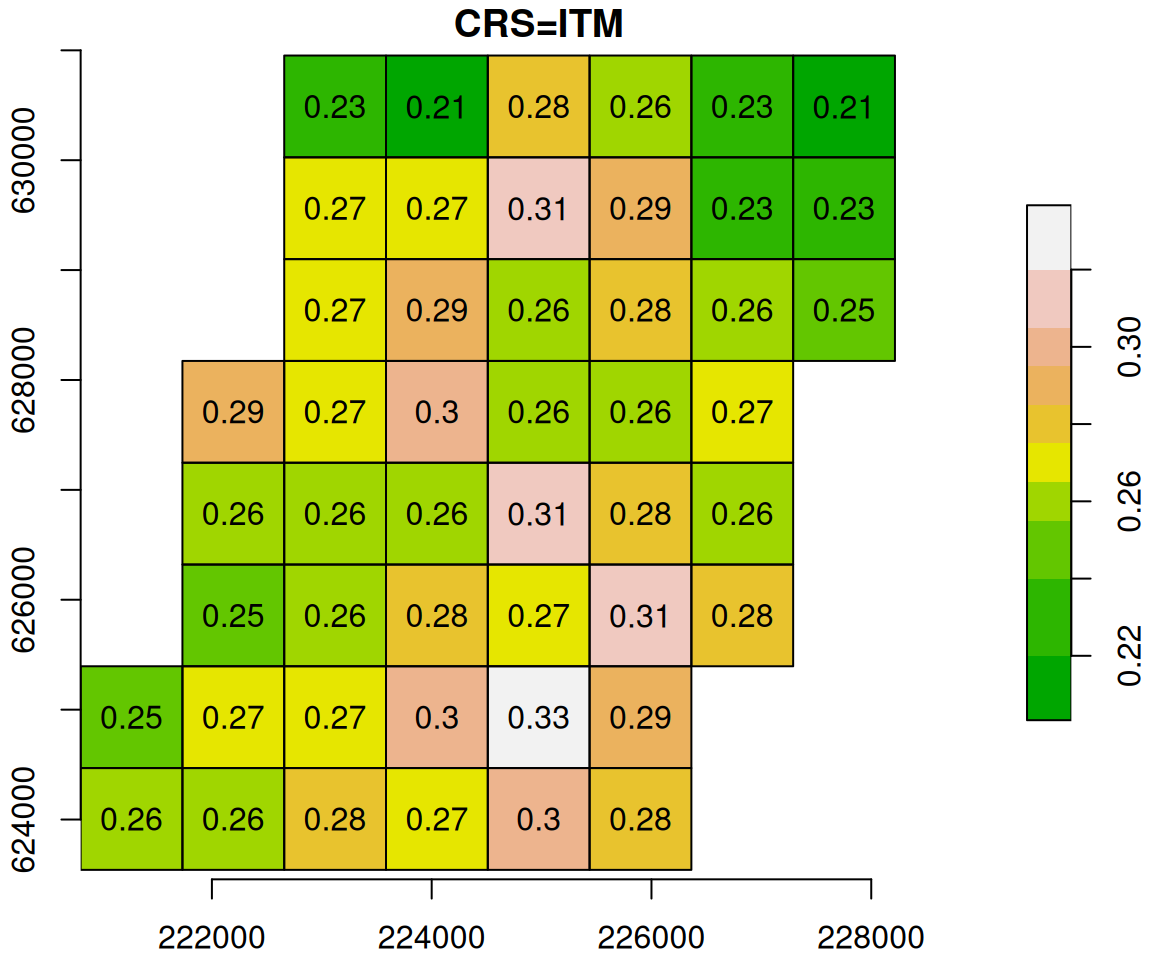
Figure 9.13: Reprojection of a small subset of the MODIS NDVI raster (left) to ITM (right)
What happens in the reprojection can be thought of as a two-step process (Figure 9.14). In the first step, the pixel outlines are reprojected as if they were polygons (Section 7.9.2), which results in an irregular grid. The grid is then resampled (Section 9.2) to form a regular grid, so that it can be represented by a raster once again.
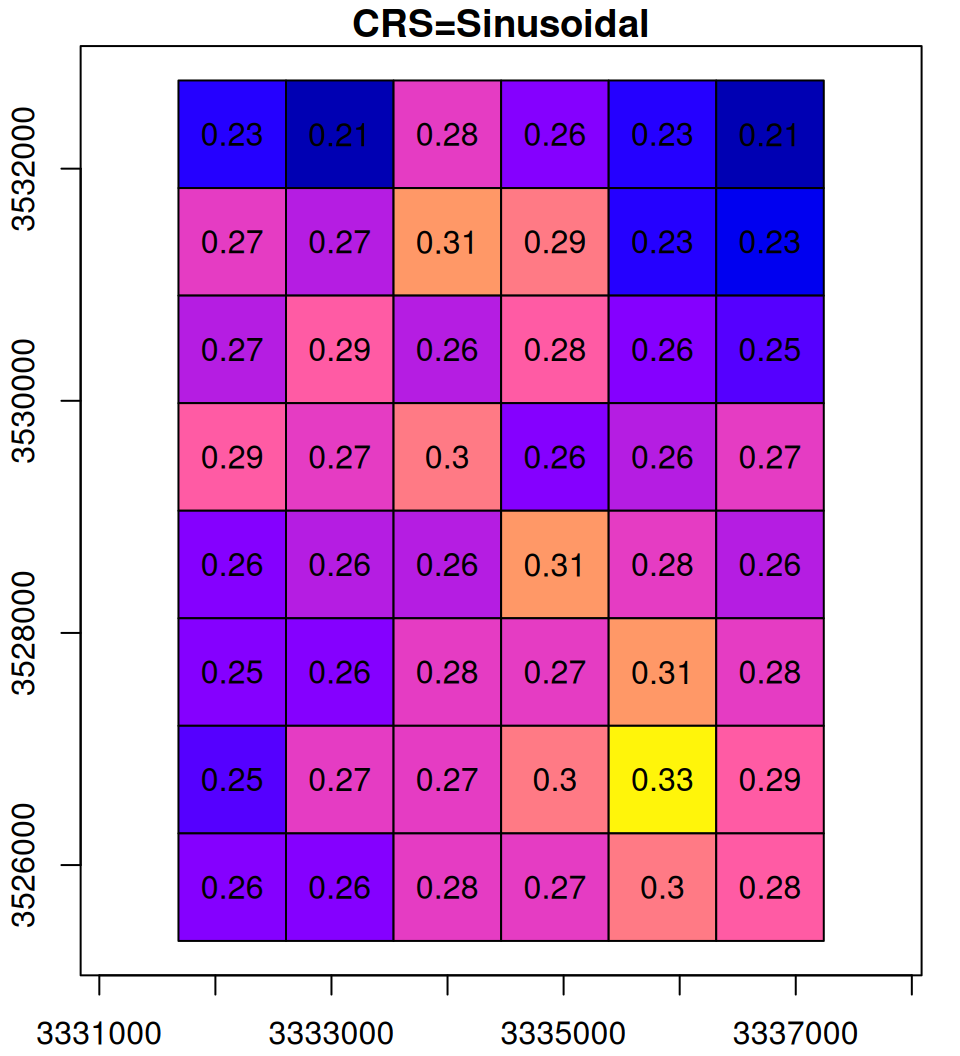
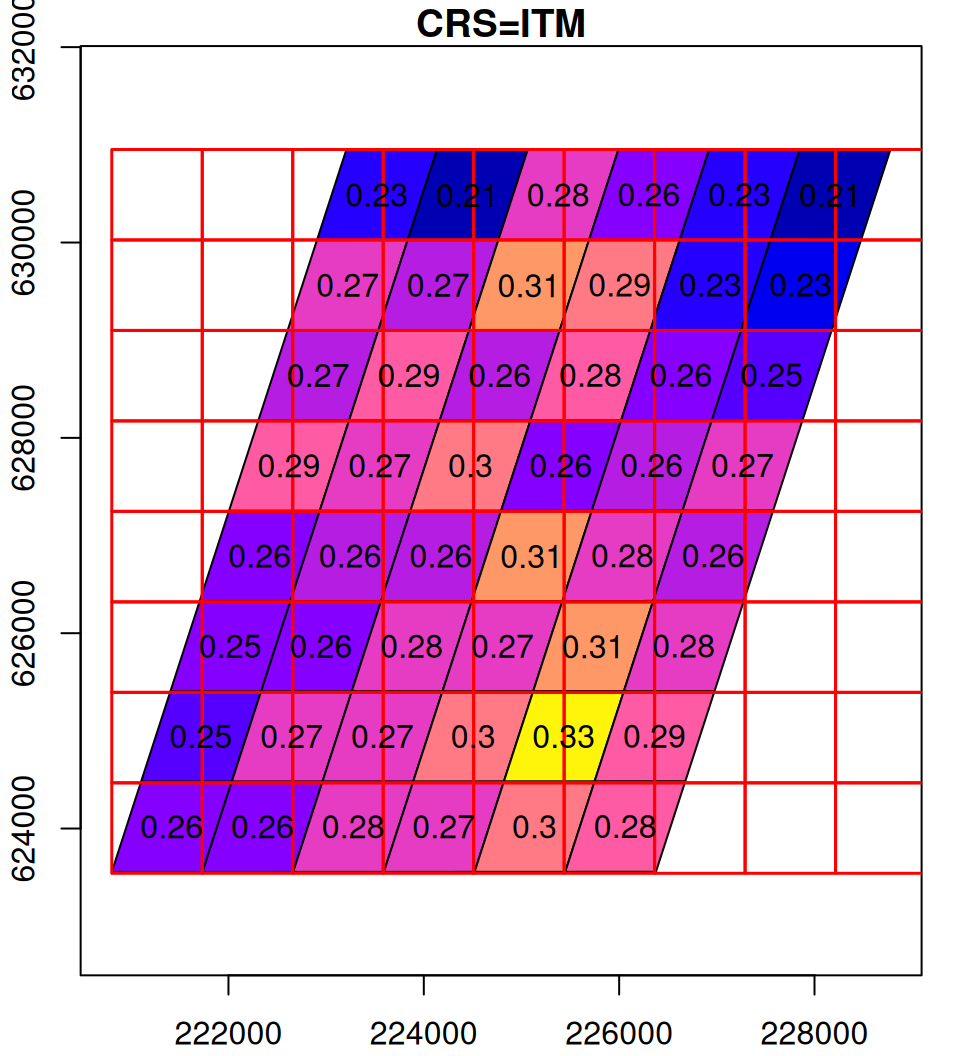
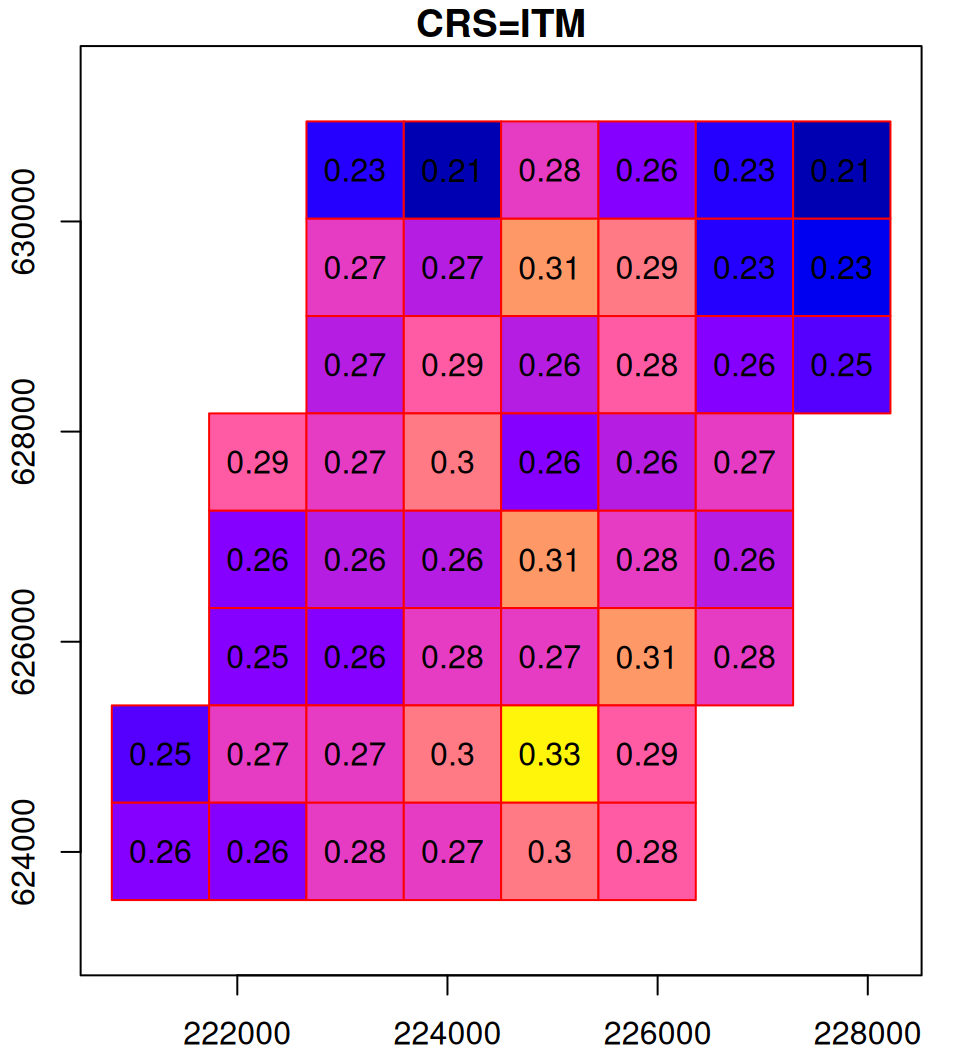
Figure 9.14: Reprojection process: the original raster (left), the reprojected raster cells as polygons (middle), and the resampled final result (right)
9.4 Focal filters
9.4.1 Introduction
So far, we only dealt with arithmetic operations that address the values of each pixel in isolation from neighboring pixels, such as in raster algebra (Sections 6.4 and 6.6.1). Another class of raster operations is where the calculation of each pixels depends on values of neighboring pixels.
The most prominent example of a raster calculation based on neighboring cells is moving window calculations, also known as focal filters. With a moving window calculation, raster values are transformed based on the values from a neighborhood surrounding each pixel. The functions applied on the neighborhood are varied, from simple functions such as mean for a low-pass filter (Section 9.4.2) to more complex functions, such as those used to calculate topographic slope and aspect (Section 9.4.4–9.4.5).
For example, a \(3\times3\) mean filter applied on a raster results in a new raster, where the values are averages of \(3\times3\) neighborhoods centered on that pixel. In Figure 9.15, the highlghted value in the output on the right (18.7) is the average of the highlighted \(3\times3\) neighborhood of the input on the left:
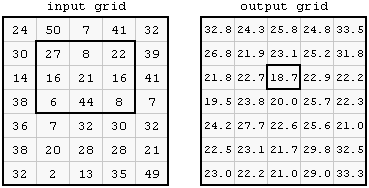
Figure 9.15: Focal filter (http://courses.washington.edu/gis250/lessons/raster_analysis1/index.html)
9.4.2 Low pass filter
9.4.2.1 What is a low pass filter?
The purpose of the mean, or low-pass, filter (Figure 9.15) is to produce a smoothed image, where extreme values (possibly noise) are cacelled out. For example, the result of applying a \(3\times3\) mean filter on a uniform image with one extreme value is shown in Figure 9.16.
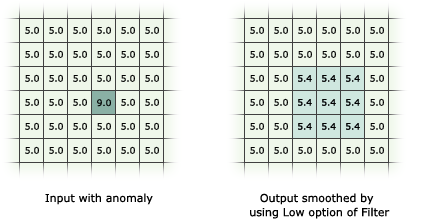
Figure 9.16: Low pass filter excample (http://desktop.arcgis.com/en/arcmap/10.3/tools/spatial-analyst-toolbox/how-filter-works.htm)
How was the value of
5.4obtained, in the result shown in Figure 9.16?
The stars package does not, at the moment, contain a function for focal filtering35. As an exercise, we are going to create our own function for focal filtering. For simplicity, we will restrict ourselves to the case where the focal “window” is \(3\times3\) pixels—which is the most common case.
Our working plan is as follows:
- Write a function named
get_neighborsthat accepts a position of the focal cell (row & column) in amatrix, and returns the 9 values of its \(3\times3\) pixel neighborhood - Write another function named
focal2that accepts a two-dimensionalstarsobject and a functionfun, iterates over the cells and appliesfunon all \(3\times3\) pixel neighborhoods extracted usingget_heighbors
9.4.2.2 The get_neighbors function
We start with a function that accepts a position (row & column) in a matrix and returns a numeric vector with the \(3\times3\) neighborhood, hereby named get_neighbors. The function accepts a matrix m and a position pos. The pos argument is a vector of length two, of the form c(row,column). The function extracts the 9 values in the respective \(3\times3\) neighborhood and returns them as a vector of length 9:
get_neighbors = function(m, pos) {
i = (pos[1]-1):(pos[1]+1)
j = (pos[2]-1):(pos[2]+1)
as.vector(t(m[i, j]))
}For example, suppose we have a \(5\times5\) matrix m:
m = matrix(1:25, ncol = 5, nrow = 5)
m
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 6 11 16 21
## [2,] 2 7 12 17 22
## [3,] 3 8 13 18 23
## [4,] 4 9 14 19 24
## [5,] 5 10 15 20 25Using get_neighbors, we can get the values of just about any \(3\times3\) neighborhood except for the outermost rows and columns (see below). For example, the following expression returns the values of the neighborhood centered on row 3, column 4:
How does the get_neighbors function work? The function first calculates the required range of rows and columns:
Then, the function extracts the corresponding matrix subset:
transposes it:
and converts to a vector:
Transposing is necessary so that the matrix values are returned by row, rather than the default by column (Section 5.1.4.1).
Note that our function is not designed to operate on the matrix edges, where the \(3\times3\) neighborhood is incomplete. For example, the following expression produces an error:
9.4.2.3 The focal2 function
Now, let’s see how we can use the get_neighbors function to apply a focal filter on a raster. We will use the dem.tif small DEM for demonstration:
First, we create a copy of the raster, named template. The template raster will be used as a “template” when converting the filtered matrix back to a stars object:
Next, we extract the raster values as a matrix:
Note that the function relies on the fact that the stars object has just two dimensions (x and y), in which case input is going to be a matrix. The matrix is transposed, using t, to maintain the right orientation of the values matrix (Figure 6.11). This is important when using functions that distinguish between the north-south and east-west directions, such as topographic aspect (Section 9.4.5).
Next, we create another matrix to hold the output values. The values are initially set to NA:
Now comes the actual computation. We are using two for loops to go over all raster cells, excluding the first and last rows and columns. For each cell, we:
- extract the \(3\times3\) neighborhood
[i,j], - apply a function—such as
mean, in this case—on the vector of extracted values, and - place the result into the corresponding cell
[i,j]in the output.
The complete code of the for loops is as follows:
for(i in 2:(nrow(input) - 1)) {
for(j in 2:(ncol(input) - 1)) {
v = get_neighbors(input, c(i, j))
output[i, j] = mean(v, na.rm = TRUE)
}
}Note that the function starts at row i=2 and ends at row i=nrow(input)-1. Similarly, it starts at column j=2 and ends at j=ncol(input)-1.
In the end, when both for loops have been completed, the output matrix contains the new, filtered, raster values. What is left to be done is to put the matrix of new values into the template, to get back a stars object. We are using t once again, to transform the matrix back into the “stars” arrangement (Figure 6.11):
The original image (x) and the filtered image (template) are shown in Figure 9.17. The figure highlights one \(3\times3\) neighborhood in the input, and the corresponding average of that neighborhood in the output36.
col = terrain.colors(5)
plot(x, text_values = TRUE, col = col, key.pos = 4, reset = FALSE, main = "input")
plot(st_geometry(st_as_sf(x, na.rm = FALSE)), border = "grey", add = TRUE)
plot(st_geometry(st_as_sf(x[,4:6,6:8])), lwd = 2, add = TRUE)
plot(round(template, 1), text_values = TRUE, col = col, key.pos = 4, reset = FALSE, main = "output")
plot(st_geometry(st_as_sf(template, na.rm = FALSE)), border = "grey", add = TRUE)
plot(st_geometry(st_as_sf(template[,5,7])), lwd = 2, add = TRUE)
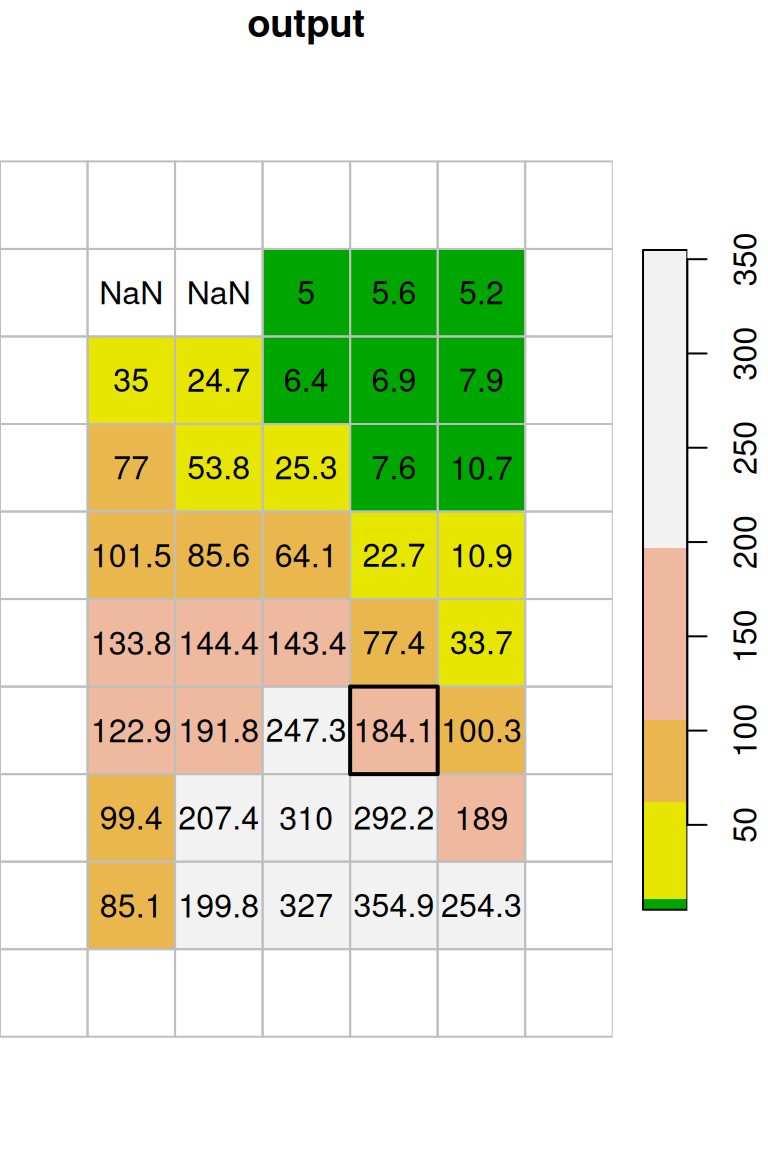
Figure 9.17: Focal filter with the mean function (left: input, right: result)
Why do the outermost rows and columns in Figure 9.17 appear empty? Which value do these pixels contain, and where did it come from?
Let’s manually check the calculation of the \(3\times3\) neighborhood highlighted in Figure 9.17:
Why do you think we got
NaNvalues in some of the cells? Can you simulate the situation to see how anNaNvalue is produced? What can we do to getNA, instead, in those pixes that getNaN?
Wrapping up our code in a function, called focal2, can be done as follows. The input raster and the function are replaced with parameters named r and fun, respectively:
focal2 = function(r, fun) {
template = r
input = t(template[[1]])
output = matrix(NA, nrow = nrow(input), ncol = ncol(input))
for(i in 2:(nrow(input) - 1)) {
for(j in 2:(ncol(input) - 1)) {
v = get_neighbors(input, c(i, j))
output[i, j] = fun(v)
}
}
template[[1]] = t(output)
return(template)
}How can we pass additional parameters to the function we use, such as na.rm=TRUE for mean? The special dots ... argument is used for that. Now, any additional argument(s) passed to focal2 (such as na.rm=TRUE) will be passed on as additional argument(s) to fun:
focal2 = function(r, fun, ...) {
template = r
input = t(template[[1]])
output = matrix(NA, nrow = nrow(input), ncol = ncol(input))
for(i in 2:(nrow(input) - 1)) {
for(j in 2:(ncol(input) - 1)) {
v = get_neighbors(input, c(i, j))
output[i, j] = fun(v, ...)
}
}
template[[1]] = t(output)
return(template)
}Now that we have a custom focal filter function focal2, let’s try to apply a different filter, such as a maximum filter:
x_max = focal2(x, max, na.rm = TRUE)
## Warning in fun(v, ...): no non-missing arguments to max; returning -Inf
## Warning in fun(v, ...): no non-missing arguments to max; returning -InfThe reason for the warnings produced by the above expression is that max applied on an empty vector gives -Inf.
t(x_max[[1]])
## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## [1,] NA NA NA NA NA NA NA
## [2,] NA -Inf -Inf 6 9 9 NA
## [3,] NA 61 61 9 10 16 NA
## [4,] NA 132 132 132 11 27 NA
## [5,] NA 254 254 254 146 27 NA
## [6,] NA 254 340 340 340 163 NA
## [7,] NA 254 383 448 448 448 NA
## [8,] NA 253 383 448 448 448 NA
## [9,] NA 253 383 448 448 448 NA
## [10,] NA NA NA NA NA NA NATo get NA instead, we can use a slightly more complex function that first checks if particular neighborhood contains any non-NA values, any only then applies max:
Recall that we used the same principle when applying the min and max functions with st_apply (Section 6.6.1.4).
The resulting raster x_max is shown in Figure 9.18. Indeed, every pixel value in the output raster is the maximal value among the values in its \(3\times3\) neighborhood:
col = terrain.colors(10)
plot(x, text_values = TRUE, breaks = "equal", col = col, key.pos = 4, reset = FALSE, main = "input")
plot(st_geometry(st_as_sf(x, na.rm = FALSE)), border = "grey", add = TRUE)
plot(st_geometry(st_as_sf(x[,4:6,6:8])), lwd = 2, add = TRUE)
plot(x_max, breaks = "equal", text_values = TRUE, col = col, key.pos = 4, reset = FALSE, main = "output")
plot(st_geometry(st_as_sf(x_max, na.rm = FALSE)), border = "grey", add = TRUE)
plot(st_geometry(st_as_sf(x_max[,5,7])), lwd = 2, add = TRUE)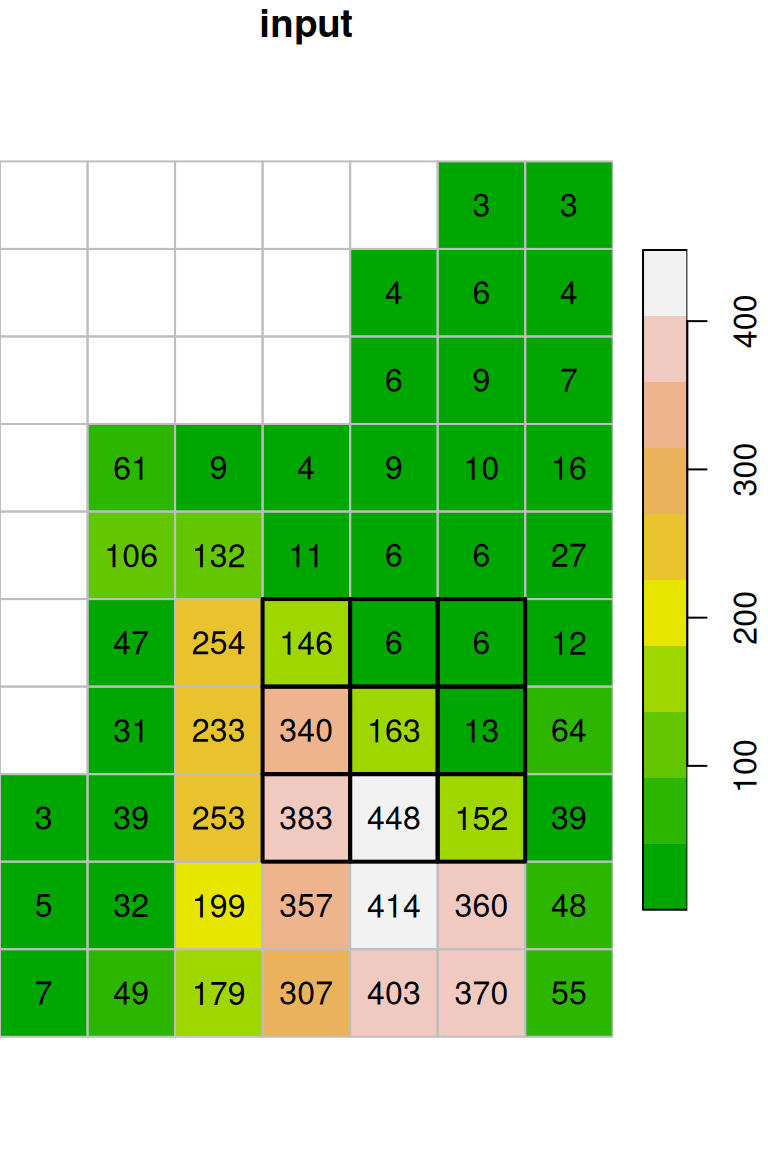
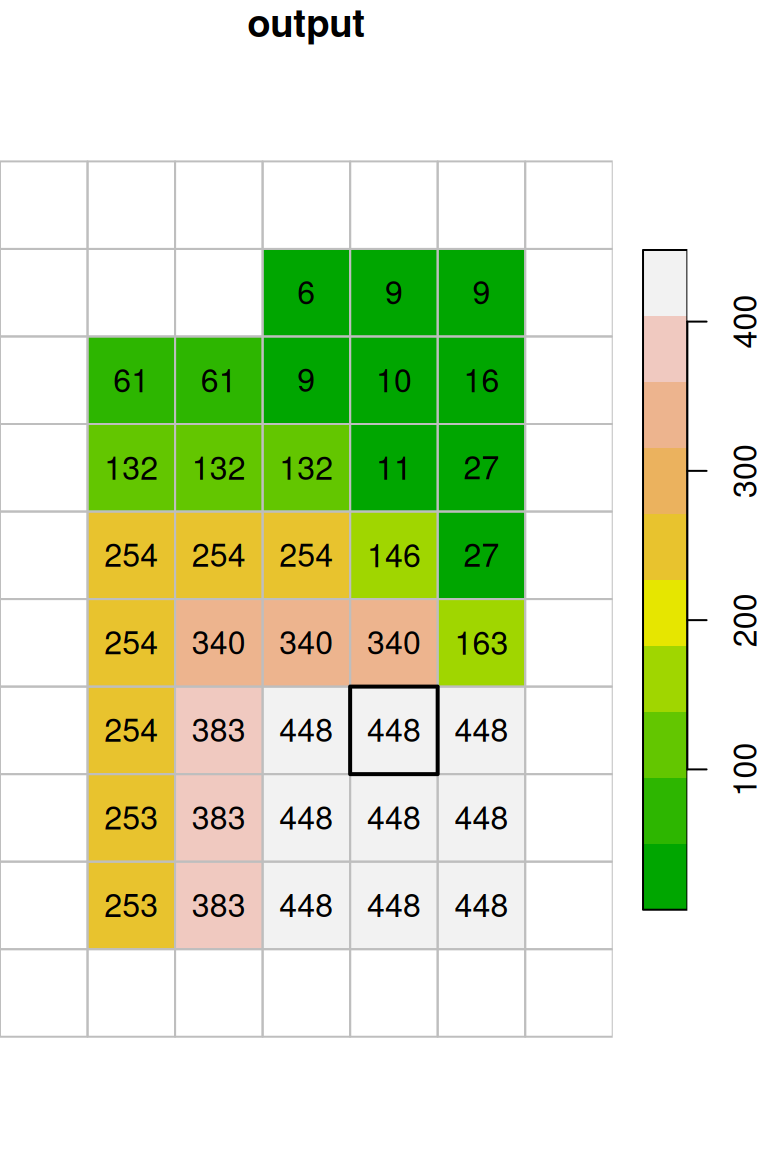
Figure 9.18: Focal filter with the max function (left: input, right: result)
Let’s try the focal2 function on another, bigger raster. For example, we can apply a low pass (i.e., mean) filter on the first layer of the MODIS NDVI raster, as follows:
The original image and the filtered result are shown in Figure 9.19:
plot(r_itm1, col = hcl.colors(11, "Spectral"), main = "input")
plot(r_itm1_mean, col = hcl.colors(11, "Spectral"), main = "output")
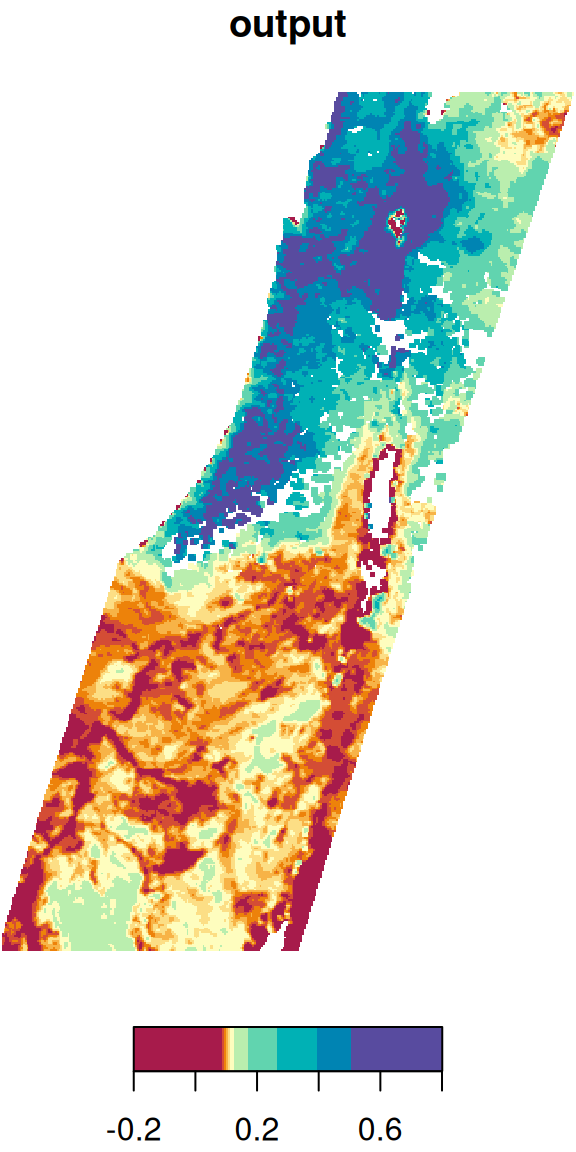
Figure 9.19: Low pass filter result
Why are there
NAareas in the raster, even though we usedna.rm=TRUE?
9.4.3 Maximum filter
For another example, let’s reconstruct the l_rec raster (Section 6.5):
l = read_stars("data/landsat_04_10_2000.tif")
red = l[,,,3, drop = TRUE]
nir = l[,,,4, drop = TRUE]
ndvi = (nir - red) / (nir + red)
names(ndvi) = "NDVI"
l_rec = ndvi
l_rec[l_rec < 0.2] = 0
l_rec[l_rec >= 0.2] = 1Given a raster with 0 and 1 values, such as l_rec, we may want to convert all 0 cells neighboring to a 1 cell to become 1. That way, for instance, the areas of the planted forests we see in the center of the image will be come more continuous, which will make it easier to transform those areas into polygons (Section 10.3.2). This can be achieved with a focal filter and the max function:
The original raster and the filtered result are shown in Figure 9.20:
plot(l_rec, col = c("grey90", "darkgreen"), main = "input")
plot(l_rec_focal, col = c("grey90", "darkgreen"), main = "output")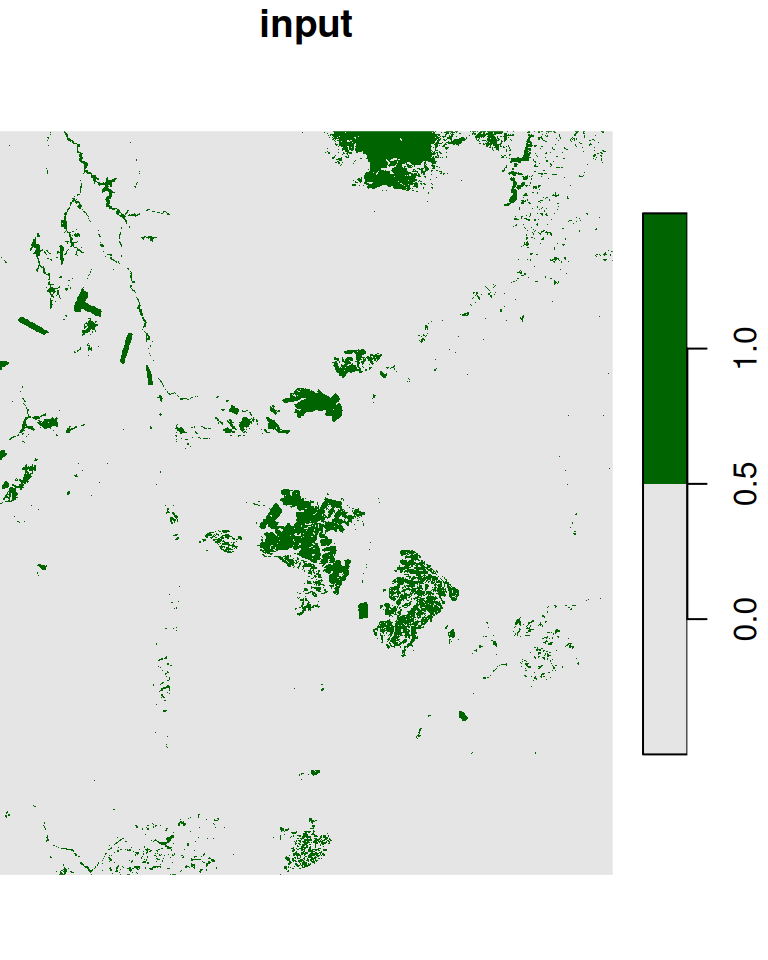
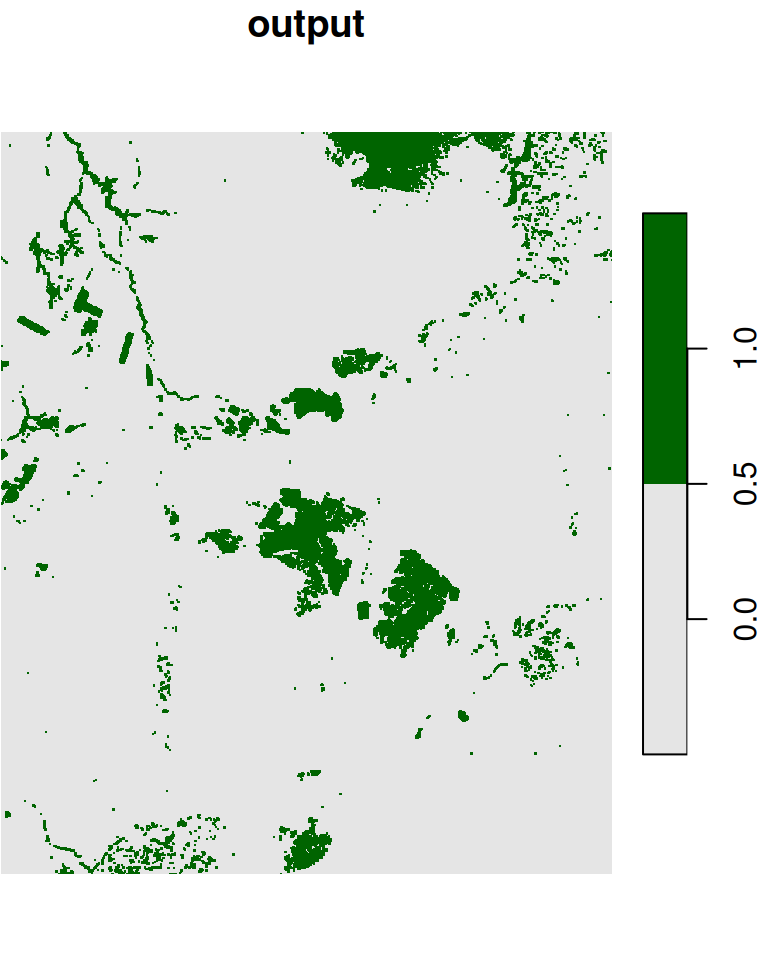
Figure 9.20: “Buffering” 1 values in a raster with 0s and 1s, using a focal filter with max
9.4.4 Topographic slope
So far we saw examples where the focal function is a simple built-in one, such as mean or max. In some cases, it is required to use a more complex function. For example, topographic indices such as slope and aspect employ complex functions where direction matters: each of the nine pixels in the \(3\times3\) neignborhood is treated differently.
For example, to calculate topographic slope based on elevation values in a \(3\times3\) neignborhood, the following function can be used. Note that the slope calulation also depends on raster resolution, which is passed as an additional parameter named res:
slope = function(x, res) {
dzdx = ((x[3] + 2*x[6] + x[9]) - (x[1] + 2*x[4] + x[7])) / (8 * res)
dzdy = ((x[7] + 2*x[8] + x[9]) - (x[1] + 2*x[2] + x[3])) / (8 * res)
atan(sqrt(dzdx^2 + dzdy^2)) * (180 / pi)
}We will not go into details on how the function works. You may refer to the How slope works article in the ArcGIS documentation for an explanation.
For example:
The slope function can be passed to focal2 to apply the slope calculation on the entire dem raster:
It is also convenient to set raster units with set_units (Section 8.3.2.2). The units of slope are decimal degrees (°):
The resulting topographic slope raster is shown in the left panel in Figure 9.21.
9.4.5 Topographic aspect
Another function, as shown below, can be used to calculate topographic aspect:
aspect = function(x) {
dzdx = ((x[3] + 2*x[6] + x[9]) - (x[1] + 2*x[4] + x[7])) / 8
dzdy = ((x[7] + 2*x[8] + x[9]) - (x[1] + 2*x[2] + x[3])) / 8
a = (180 / pi) * atan2(dzdy, -dzdx)
if(is.na(a)) return(NA)
if (a < 0) a = 90 - a else
if (a > 90) a = 360 - a + 90 else
a = 90 - a
return(a)
}For details on how the function works, see the How aspect works article in the ArcGIS documentation.
For example:
Again, the aspect function can be passed to focal2 to apply it on the entire raster:
dem_aspect = focal2(dem, aspect)
names(dem_aspect) = "aspect"
dem_aspect[[1]] = set_units(dem_aspect[[1]], "degree")The resulting topographic aspect raster is shown in the right panel in Figure 9.21:
plot(dem_slope, breaks = "equal", col = rev(hcl.colors(11, "Spectral")), key.pos = 4)
plot(dem_aspect, breaks = "equal", col = hcl.colors(11, "Spectral"), key.pos = 4)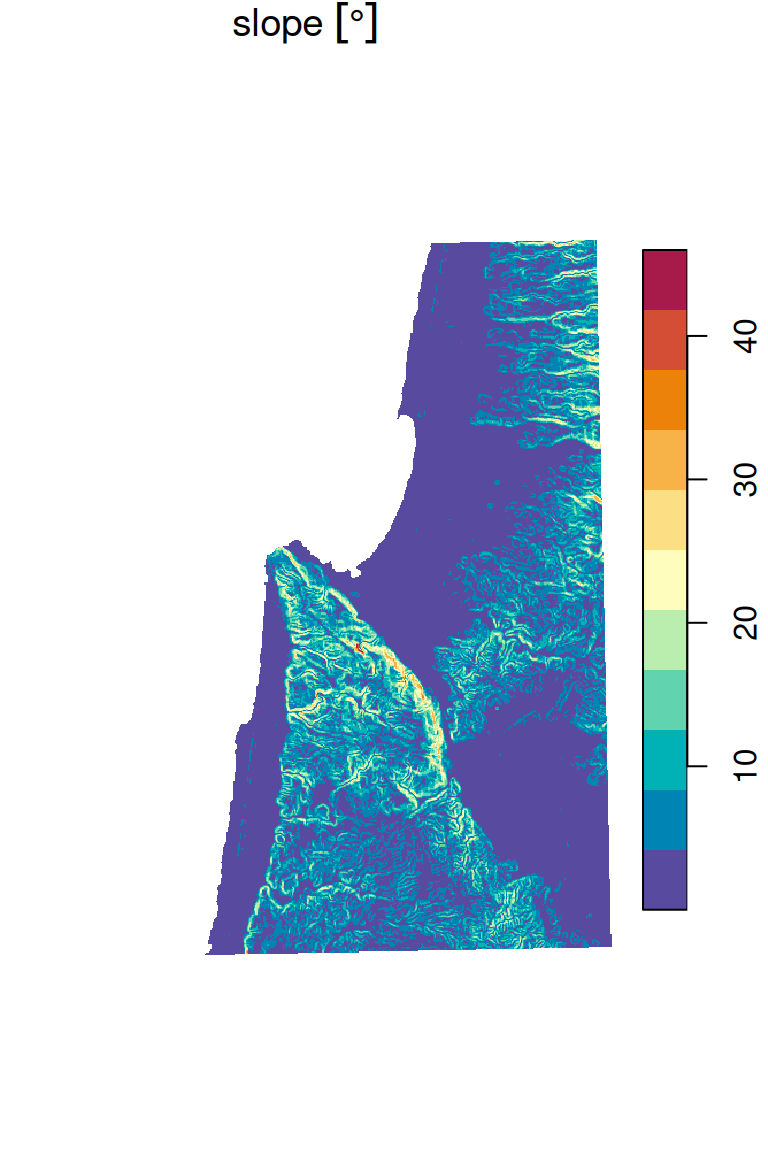
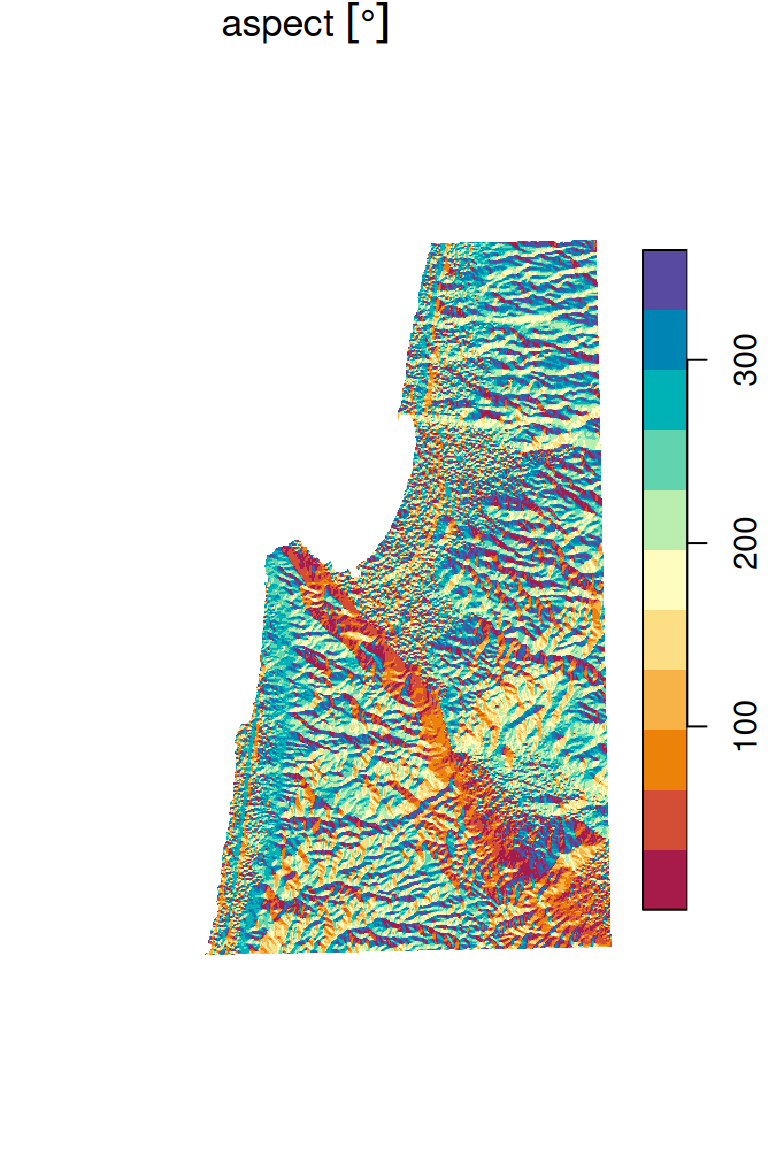
Figure 9.21: Topographic slope (left) and topographic aspect (right)
Note that our custom focal2+get_neighbors functions are quite minimal, and can be improved in several ways:
- Being able to set neighbor sizes other than \(3\times3\)
- Dealing with the first/last rows and and columns
- Dealing with rasters that have more than two dimensions (separate filter per dimension? a three-dimensional filter?)
- Making the calculation more efficient (e.g., using C/C++ code inside R or using parallel computation)